The first two talks in this session
Explicit and Optimal Exact-Regenerating Codes for the Minimum-Bandwidth Point in Distributed Storage by K. V. Rashmi , Nihar B. Shah , P. Vijay Kumar , Kannan Ramchandran
and
A Flexible Class of Regenerating Codes for Distributed Storage by Nihar B. Shah, K. V. Rashmi, P. Vijay Kumar
where given by Vijay Kumar. To summarize the results in these two papers (and also
Exact-Repair MDS Codes for Distributed Storage Using Interference Alignment
by Changho Suh and Kannan Ramchandran
that appeared in another session), it is useful to briefly explain the current landscape of the repair problem:
(for more information see the Distributed storage wiki and this survey paper which however do not contain these new results yet.)
Assume a file to be stored, of size  (sometimes also found as
(sometimes also found as 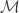 in the literature) one can use an
in the literature) one can use an  MDS code for storage with maximum reliability: just cut the file into
MDS code for storage with maximum reliability: just cut the file into  packets of size
packets of size  , encode into
, encode into  pieces (of the same size
pieces (of the same size  ) and store each packet into a storage node. The reliability achieved is that any storage nodes contain enough information to recover the file, which is the best possible. So we can tolerate any
) and store each packet into a storage node. The reliability achieved is that any storage nodes contain enough information to recover the file, which is the best possible. So we can tolerate any 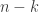 failures without losing data. But most of the time we only have one failure. We then want to repair this failure by creating a new encoded packet by communicating as little information as possible from
failures without losing data. But most of the time we only have one failure. We then want to repair this failure by creating a new encoded packet by communicating as little information as possible from  surviving storage nodes. There are two cases:
surviving storage nodes. There are two cases:
1. If we ask that the new packet still forms a good code (i.e. any out of the new nodes suffice to recover), the problem is called functional repair and is completely solved and equivalent to multicasting. The minimum repair bandwidth can be determined by a cut-set bound and we will refer to the achievable region as the cut-set region.
2. If we ask that the new packet formed is exactly identical to the lost one: This problem is called exact repair and is very difficult. It is equivalent to a multicasting network coding problem with intermediate nodes having requests for subsets and therefore prior tools from network coding do not suffice. The repair problem seems close to locally decodable codes but this connection has not been investigated yet.
The amount of information communicated from surviving nodes is called the repair bandwidth  . Another issue is that one can reduce this repair bandwidth if the storage per node
. Another issue is that one can reduce this repair bandwidth if the storage per node  is allowed to increase and there is a tradeoff involved.
is allowed to increase and there is a tradeoff involved.
The two most important points of this tradeoff are called Minimum Storage point (MSR) (where corresponds to MDS codes) and Minimum Bandwidth point (MBR) (where is larger but the repair bandwidth is minimized).
Clearly exact repair is a strictly harder than functional repair and the cut-set region is still a valid outer bound. A substantial amount of recent work has been focused on understanding the communication required for exact repair. All the results here establish that the cut-set region is achievable for exact repair for the parameters discussed.
Vijay presented a storyline that concluded to the settings which were known before.
This paper had completely solved the problem for the Minimum Bandwidth (MBR) point, for any , but fixing  .
.
The first paper (Explicit and Optimal Exact-Regenerating Codes for the Minimum-Bandwidth Point in Distributed Storage) in this session established that the MBR cut-set bound point can be achieved with exact repair for any , corresponding to an arbitrary number  of failed nodes. The second result in this paper is that all the other interior points of the tradeoff curve (except the points of minimum repair and minimum storage) cannot be achieved with linear codes for exact repair. ( Of course this does not preclude the possibility that they can be approached infinitely close by making the code packets smaller and smaller).
of failed nodes. The second result in this paper is that all the other interior points of the tradeoff curve (except the points of minimum repair and minimum storage) cannot be achieved with linear codes for exact repair. ( Of course this does not preclude the possibility that they can be approached infinitely close by making the code packets smaller and smaller).
In the second paper A Flexible Class of Regenerating Codes for Distributed Storage, the authors generalize the requirements of the distributed storage system: the initial requirement was that any data collector who connects to any storage nodes (and receives all their stored data ) obtains enough information to recover the file. Here the authors want to enable data collectors who have limited communication with each storage node to reconstruct the file. The only requirement is that the total amount of information communicated is sufficient. This is, of course, a harder requirement on the storage code and the authors characterize the repair bandwidth for functional repair under this new requirement of flexible recovery. The technical part involves graph theoretically bounding the flow for these flexible information flow graphs. The question of exact repair of these flexible regenerating codes naturally arises and it seems to me that previous exact regenerating code constructions do not immediately generalize.
Finally, in another session was the closely related paper
Exact-Repair MDS Codes for Distributed Storage Using Interference Alignment
by Changho Suh and Kannan Ramchandran
Changho presented two new results: both are for the minimum storage point (MSR) and hence correspond to results for MDS codes.
One is that for the low-rate regime  if the number of nodes helping for the repair is sufficiently large
if the number of nodes helping for the repair is sufficiently large  , the MSR cut-set point can be achived for exact repair. For this regime the paper presents explicit code constructions that use a small finite fields and build on this paper which established similar results but only when repairing systematic nodes (and not nodes storing parities).
, the MSR cut-set point can be achived for exact repair. For this regime the paper presents explicit code constructions that use a small finite fields and build on this paper which established similar results but only when repairing systematic nodes (and not nodes storing parities).
The second result of this paper closes the open problem of MSR exact repair for the high-rate 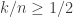 regime. The paper uses the symbol extension technique introduced in the Cadambe-Jafar paper Interference Alignment and the Degrees of Freedom for the K User Interference Channel to MDS codes that asymptotically approach the cut-set bound.
regime. The paper uses the symbol extension technique introduced in the Cadambe-Jafar paper Interference Alignment and the Degrees of Freedom for the K User Interference Channel to MDS codes that asymptotically approach the cut-set bound.
This paper appeared simultaneously with
Distributed Data Storage with Minimum Storage Regenerating Codes – Exact and Functional Repair are Asymptotically Equally Efficient, by Viveck R. Cadambe, Syed A. Jafar, Hamed Maleki,
Which independently obtain very similar results using the same technique. Note that the symbol extension approach requires vector linear network coding (sub-packetization of each stored packet) and to approach the cut-set bound an enormous amount of subpacketization (and field size) seem to be required. I think it is correct to interpret these results as existence proofs of high-rate regenerating codes approaching the cut-set bound for exact repair, rather than explicit constructions.
I think that the applicability of interference alignment to problems that seem to have nothing to do with wireless channels is quite remarkable. Another related case is the paper
Network Coding for Multiple Unicasts: An Interference Alignment Approach
by A. Das, S. Vishwanath, S. Jafar, A. Markopoulou.
I will blog my notes on this paper (hopefully) soon. Are the slides available anywhere? I took pictures of slides from other talks but my camera run out of battery.
 called the symmetrizability of the channel such that for list-decoding with list sizes
called the symmetrizability of the channel such that for list-decoding with list sizes  the capacity is 0 and for larger list sizes the capacity is the randomized coding capacity of the AVC. This work extended this to the multiaccess setting, which is a particularly tricky beast since the capacity region itself is nonconvex. He showed that there is a
the capacity is 0 and for larger list sizes the capacity is the randomized coding capacity of the AVC. This work extended this to the multiaccess setting, which is a particularly tricky beast since the capacity region itself is nonconvex. He showed that there is a  such that the capacity region has empty interior if the list size is
such that the capacity region has empty interior if the list size is  and that for list sizes
and that for list sizes  you get back the randomized coding capacity. What is open is whether the list sizes for the two users can be different, so that this gap could be closed, but that problem seems pretty hard to tackle.
you get back the randomized coding capacity. What is open is whether the list sizes for the two users can be different, so that this gap could be closed, but that problem seems pretty hard to tackle. based on
based on  , where
, where  is the delay parameter. Suppose everything is binary and the adversary gets to flip a total of
is the delay parameter. Suppose everything is binary and the adversary gets to flip a total of 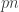 bits of the codeword but has to see it causally with delay
bits of the codeword but has to see it causally with delay 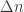 . If
. If 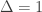 the adversary sees nothing and the average-error capacity is
the adversary sees nothing and the average-error capacity is  bits. If
bits. If 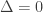 the adversary can do a lot worse and the capacity is
the adversary can do a lot worse and the capacity is  bits. What we show is that for any
bits. What we show is that for any  we go back to
we go back to  regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by
regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by  check nodes, if we take
check nodes, if we take  to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form
to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form 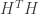 and look at its eigenvalues
and look at its eigenvalues and Tanner’s spectral bound on expansion is that expansion
and Tanner’s spectral bound on expansion is that expansion  is greater than
is greater than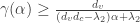 for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any
for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any  , which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book
, which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book  girth with high probability. When we actually tried to find a proof for this, for example looking at the
girth with high probability. When we actually tried to find a proof for this, for example looking at the  probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs.
probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs. bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system?
bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system? measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the
measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the  measurement matrix has
measurement matrix has  non-zeros. (see our recent
non-zeros. (see our recent  i.i.d. individuals with characteristics distributed according to
i.i.d. individuals with characteristics distributed according to 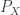 and features
and features  conditioned on the individuals according to
conditioned on the individuals according to  . The identification problem is this: given a noisy feature vector
. The identification problem is this: given a noisy feature vector  generated from a particular individual
generated from a particular individual  retrieve the index of the user corresponding to
retrieve the index of the user corresponding to  , so they are trading off identification and distortion. The solution is to code
, so they are trading off identification and distortion. The solution is to code  features and the
features and the  . So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits
. So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits  . A user with side information
. A user with side information 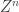 can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
 and only send the projections. The error detection works since the projected data follows the same
and only send the projections. The error detection works since the projected data follows the same  using a small seed
using a small seed  , and project on that. All the storage nodes need to share the small seed
, and project on that. All the storage nodes need to share the small seed  .
.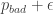 where
where  is the total variation bound obtained from the pseudo-random generator.
is the total variation bound obtained from the pseudo-random generator. nodes in an
nodes in an ![[0,A]](https://s0.wp.com/latex.php?latex=%5B0%2CA%5D&bg=ffffff&fg=333333&s=0&c=20201002) in which
in which  . The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know
. The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know  , however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on.
, however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on. you get a central limit theorem (CLT). What if you normalize by
you get a central limit theorem (CLT). What if you normalize by 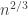 for example? It turns out you get something like
for example? It turns out you get something like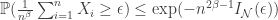
 is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps
is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps 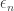 to capacity the error decays like
to capacity the error decays like  , where
, where  is the dispersion of the channel.
is the dispersion of the channel. . These give matching scalings up to the first three terms as
. These give matching scalings up to the first three terms as 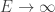 . The first term is
. The first term is 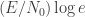 . Interestingly, with feedback, they show that the first term is
. Interestingly, with feedback, they show that the first term is  times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy
times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy  you can send
you can send  messages with 0 error.
messages with 0 error.