Mike Rabbat pointed out his new preprint on ArXiv:
Broadcast Gossip Algorithms for Consensus on Strongly Connected Digraphs
Wu Shaochuan, Michael G. Rabbat
The basic starting point is the unidirectional Broadcast Gossip algorithm — we have 


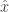

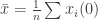
![\mathbb{E}[\hat{x}] = \bar{x}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%7Bx%7D%5D+%3D+%5Cbar%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The reason broadcast gossip does’t compute the average is pretty clear — since the communication and updates are unidirectional, the average of the nodes’ values changes over time. One way around this is to use companion variables 
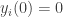





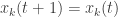

So what’s going on here? Each time a node transmits it resets its companion variable to 
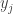
The parameters of the algorithm are matrices 




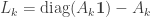

When node
![W_k \left[ \begin{array}{cc} I - L_k & \epsilon D_k \\ L_k & S_k - \epsilon D_k \end{array} \right]](https://s0.wp.com/latex.php?latex=W_k+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+-+L_k+%26+%5Cepsilon+D_k+%5C%5C+L_k+%26+S_k+-+%5Cepsilon+D_k+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
such that
![\left[ \begin{array}{c} \mathbf{x}(t+1) \\ \mathbf{y}(t+1) \end{array} \right]^T = W(t) \left[ \begin{array}{c} \mathbf{x}(t) \\ \mathbf{y}(t) \end{array} \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%2B1%29+%5C%5C+%5Cmathbf%7By%7D%28t%2B1%29+%5Cend%7Barray%7D+%5Cright%5D%5ET+%3D+W%28t%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%29+%5C%5C+%5Cmathbf%7By%7D%28t%29+%5Cend%7Barray%7D+%5Cright%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
where 
The main results are:
- If we choose
small enough, then
and
under more conditions.
- A sufficient condition for the second moment of the error to go to 0.
- Rules on how to pick the parameters, especially
There are also some nice simulations. Broadcast gossip is nice because of its simplicity, and adding a little monitoring/control variable 

 where
where  is the maximum degree in the graph. They also showed the barbell graph is very very slow.
is the maximum degree in the graph. They also showed the barbell graph is very very slow. grid with the top and left edges wrapped around to connect with the bottom and right edges. Every vertex has 4 neighbors. Now imagine a very lazy random walk on this graph in which a random walker moves from vertex
grid with the top and left edges wrapped around to connect with the bottom and right edges. Every vertex has 4 neighbors. Now imagine a very lazy random walk on this graph in which a random walker moves from vertex  to one of its neighbors with probability
to one of its neighbors with probability  . It’s “well known” that this random walk takes around
. It’s “well known” that this random walk takes around  steps to mix. That is, if
steps to mix. That is, if  is the matrix of transition probabilities then
is the matrix of transition probabilities then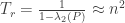
 is the second largest eigenvalue of
is the second largest eigenvalue of  is the inverse of the spectral gap of the matrix. One way of characterizing
is the inverse of the spectral gap of the matrix. One way of characterizing  on the states of the chain define the Dirichlet form
on the states of the chain define the Dirichlet form 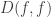 by
by
 and
and  for all edges in the graph. We write
for all edges in the graph. We write 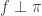 if
if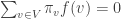
 via
via
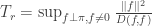
 you should choose in the grid example to get the scaling of
you should choose in the grid example to get the scaling of  is divisible by 4 and set
is divisible by 4 and set 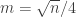 . The values for
. The values for 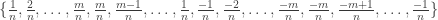

 squares scales like
squares scales like  and
and  and there are fewer than
and there are fewer than 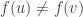 . Thus:
. Thus: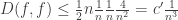
 as desired.
as desired. but in the denominator we get
but in the denominator we get  positive terms. The key is to make all the differences
positive terms. The key is to make all the differences  in the denominator small while keeping the average of
in the denominator small while keeping the average of 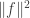 large enough. Even though you sum over
large enough. Even though you sum over  in the numerator.
in the numerator.