I wrote to Ventra a week ago to ask them if there was any way for me to get an automated notice when it would charge my bank account. This was a nice feature of the Chicago Card — by letting me know when it added another $20 I could get a rough sense of my transit usage. A week after asking, I got the following response:
Dear Customer,
I am very sorry, but at this time, we do not have any alerts set up to notify customers when their card is auto loaded with value. If you have transit auto load set up, you just have to be aware that when your balance gets to $10.00 and below, that is when the funding source you have on your acct is charged for what ever value preference you have selected to be added to your card. Or if you have Pass auto load set up, then you just need to be aware that it will always charge your funding source for the pass you have chosen and add it to your acct, three days prior to your existing pass expiring. You can keep track of your balance via your web acct on the internet or can call us to check your balance, and can also check your balance at any Ventra Vending Machine as well. We do apologize for any inconvenience this may cause, but if you have any further concerns, please feel free to contact us for assistance. Thank You And Have A Nice Day.
The old CTA system would even flash your current balance and how much was being debited when you went through. On each transaction you could tell your balance, at least at train stations. Given that I have had to tap my Ventra card 10+ times (no hyperbole) to get through a turnstile at a CTA station, I have almost no confidence that the system is charging me the correct amount. Add to that Ventra’s penchant for charging debit cards in people’s wallets without informing them, there’s only one conclusion: Ventra is wholly set up like a scam. They say “give us your bank account information and then log into our website (with its awful UI) periodically to verify that we are not overcharging you.”
I guess it’s all moot since I’m leaving Chicago, but still… arrrrrrrrrgh.
 variables. For simplicity, let’s consider an
variables. For simplicity, let’s consider an 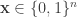 . There are
. There are  possible values, so explicitly maximizing the distribution could be computationally tricky. However we are often aided by the fact probability model has some structure. For example, the
possible values, so explicitly maximizing the distribution could be computationally tricky. However we are often aided by the fact probability model has some structure. For example, the  which assigns a score to each
which assigns a score to each 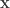 . The distribution on
. The distribution on 
 is the infamous partition function:
is the infamous partition function: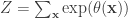
 .
. to the potential function and solves the resulting MAP problem:
to the potential function and solves the resulting MAP problem: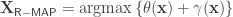
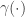 associates a random variable to each
associates a random variable to each 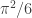 , and cumulative distribution function
, and cumulative distribution function ,
, is the
is the 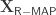 ? It turns out that the distribution is exactly that of the Gibbs distribution we want to sample from:
? It turns out that the distribution is exactly that of the Gibbs distribution we want to sample from:
![\mathbb{E}_{\gamma}\left[ \max_{\mathbf{x}} \left\{ \theta(\mathbf{x}) + \gamma(\mathbf{x}) \right\} \right] = \log Z](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Cgamma%7D%5Cleft%5B+%5Cmax_%7B%5Cmathbf%7Bx%7D%7D+%5Cleft%5C%7B+%5Ctheta%28%5Cmathbf%7Bx%7D%29+%2B+%5Cgamma%28%5Cmathbf%7Bx%7D%29+%5Cright%5C%7D+%5Cright%5D+%3D+%5Clog+Z&bg=ffffff&fg=333333&s=0&c=20201002)
 random variables, shove the perturbed potential function into our black-box MAP solver, and voilà: samples from the Gibbs distribution. Except that there’s a little problem here – we have to generate
random variables, shove the perturbed potential function into our black-box MAP solver, and voilà: samples from the Gibbs distribution. Except that there’s a little problem here – we have to generate 
 .
.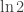 .
. .
.
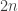 moves by flipping every card over once (there are
moves by flipping every card over once (there are  cards) to learn all of their identities and then removing all of the pairs one by one. The better strategy is
cards) to learn all of their identities and then removing all of the pairs one by one. The better strategy is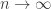 , I wonder if there is a more “probabilistic” argument (this is perhaps a bit fuzzy) for the results.
, I wonder if there is a more “probabilistic” argument (this is perhaps a bit fuzzy) for the results.