If you’re attending ISIT then you probably got an email about Trailhead, a graphical system which links papers at ISIT “based on how many authors they have in common in the references, and each paper is linked to the 4 closest neighbors.” It’s written by Jonas Arnfred, a student at EPFL. The search feature doesn’t seem to be working, but it’s a fun little app.
I wonder how different the graph would look using something like the Toronto Paper Matching System, which is used by NIPS and ICML to match papers to reviewers. One could even imagine a profiler which would help you pick out papers which would be interesting to you — you could upload 10 papers of your own or that you find interesting, and it could re-visualize the conference through that viewpoint.
I was interested in the 19 papers which had no connections. Here are a few, randomly sampled:
- Fish et al., Delay-Doppler Channel Estimation with Almost Linear Complexity
- Song and İs ̧can, Network Coding for the Broadcast Rayleigh Fading Channel with Feedback
- Bilal et al., Extensions of
-Additive Self-Dual Codes Preserving Their Properties
- Bernal-Buitrago and Simón, Partial Permutation Decoding for Abelian Codes
- Kovalev and Pryadko, Improved quantum hypergraph-product LDPC codes
- Price and Woodruff, Applications of the Shannon-Hartley Theorem to Data Streams and Sparse Recovery
- Willems, Constrained Probability
- Nowak and Kays, On Matching Short LDPC Codes with Spectrally-Efficient Modulation
They seem to run the gamut, topic wise, but I think one would be hard-pressed to find many unlinked multi-user information theory papers.
On the other side, there’s a little cluster of quantum information theory papers which all have similar citations, unsurprisingly. They show up as a little clique-ish thing on the bottom right in my rendering (it may be random).
Who are my neighbors in the graph?
- Strong Secrecy in Compound Broadcast Channels with Confidential Messages — Rafael F. Wyrembelski, Holger Boche
- Lossy Source-Channel Communication over a Phase-Incoherent Interference Relay Channel — H. Ebrahimzadeh Saffar, M. Badiei Khuzani and P. Mitran
- Shannon Entropy Convergence Results in the Countable Infinite Case — Jorge Silva, Patricio Parada
- Non-adaptive Group Testing: Explicit bounds and novel algorithms — Chun Lam Chan, Sidharth Jaggi, Venkatesh Saligrama, Samar Agnihotri
- Non-coherent Network Coding: An Arbitrarily Varying Channel Approach — Mahdi Jafari Siavoshani, Shenghao Yang, Raymond Yeung
 in dimension
in dimension  , can we say whether the polytope contains an integer point? In general,
, can we say whether the polytope contains an integer point? In general,  and the sphere
and the sphere  of radius
of radius  around
around  vectors
vectors  uniformly from the surface of the unit sphere, and consider the polytope defined by faces which are tangent to
uniformly from the surface of the unit sphere, and consider the polytope defined by faces which are tangent to  for
for  . That is, the vector
. That is, the vector  . The goal is to find how
. The goal is to find how 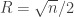 , then we will always have an integer point. What should the real scaling for
, then we will always have an integer point. What should the real scaling for  and
and 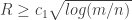 , with high probability the polytope will have an integer point for every
, with high probability the polytope will have an integer point for every 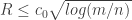 , then with high probability the polytope “centered” at
, then with high probability the polytope “centered” at  with not contain an integer point. Note that if the number of faces is linear in
with not contain an integer point. Note that if the number of faces is linear in 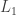 geometry gives better intuition.
geometry gives better intuition. -dimensional jointly Gaussian vector
-dimensional jointly Gaussian vector  with covariance matrix
with covariance matrix  . The differential entropy of
. The differential entropy of 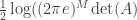 . Suppose now I consider some rank-1 perturbation
. Suppose now I consider some rank-1 perturbation  . What choice of
. What choice of  maximizes the differential entropy?
maximizes the differential entropy? positive definite matrix and
positive definite matrix and  and
and  be two
be two  matrices. Then
matrices. Then .
.
![\left[ \begin{array}{cc} A & -U \\ V^{H} & I \end{array} \right] = \left[ \begin{array}{cc} A & 0 \\ V^{H} & I \end{array} \right] \cdot \left[ \begin{array}{cc} I & - A^{-1} U \\ 0 & I + V^H A^{-1} U \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+-U+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+0+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%5Ccdot+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+%26+-+A%5E%7B-1%7D+U+%5C%5C+0+%26+I+%2B+V%5EH+A%5E%7B-1%7D+U+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,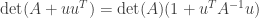
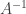 , which in this case is the smallest singular value of
, which in this case is the smallest singular value of 