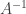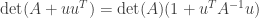I had never really heard of this result, sometimes called the Matrix Determinant Lemma, but it came up in the process of answering a relatively simple question. Suppose I have an 


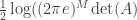


On the face of it, this seems intuitively easy — diagonalize
Matrix Determinant Lemma. Let
positive definite matrix and
and
be two
matrices. Then
.
To see this, note that
![\left[ \begin{array}{cc} A & -U \\ V^{H} & I \end{array} \right] = \left[ \begin{array}{cc} A & 0 \\ V^{H} & I \end{array} \right] \cdot \left[ \begin{array}{cc} I & - A^{-1} U \\ 0 & I + V^H A^{-1} U \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+-U+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+0+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%5Ccdot+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+%26+-+A%5E%7B-1%7D+U+%5C%5C+0+%26+I+%2B+V%5EH+A%5E%7B-1%7D+U+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
and take determinants on both sides.
So now applying this to our problem,
But the right side is clearly maximized by choosing