I’ve been thinking about reviving the blog and as maybe a way of easing back in I’ve come up with some short post ideas. As usual, these are a bit half-baked, so YMMV.
A common way of generating a “hook” in a technical talk is to say “actually, this is really an old idea.” There are two examples of this that come to mind for me, group testing and randomized response. In both of these topics, there is a “classic paper” with an “interesting historical anecdote” that generates a kind of factoid in the audience’s mind. Unfortunately, the factoid that gets stored is often incorrect.
Group testing refers to the process of finding a (small) number of “defective elements” a larger set of elements by testing groups of elements. The assumption is that the test you have is sensitive enough to flag a group as containing a defective element. This was first proposed in Robert Dorfman’s 1943 paper The Detection of Defective Members of Large Populations in The Annals of Mathematical Statistics. He introduced group testing with the application of screening for syphilis in the United States Public Health Service and the Selective Service System during WWII. A syphilis test (the Wasserman test) which is sufficiently sensitive could be used on pooled blood samples: if the test was negative the whole group is clear and if the group is positive you could test individuals in the group or further subdivide.
As noted in this paper by Gilbert and Strauss, the “Selective Service System did not put group testing for syphilis into practice because the Wassermann tests were not sensitive enough…” when pooled. That paper doesn’t have a citation but you can find it in the book by Du and Hwang:
Unfortunately, this very promising idea of grouping blood samples for syphilis screening was not actually put to use. The main reason, communicated to us by C. Eisenhart, was that the test was no longer accurate when as few as eight or nine samples were pooled. Nevertheless, test accuracy could have been improved over years, or possibly not a serious problem in screening for another disease. Therefore we quoted the above from Dorfman in length not only because of its historical significance, but also because at this age of a potential AIDS epidemic, Dorfman’s clear account of applying group testing to screen syphilitic individuals may have new impact to the medical world and the health service sector.
It seems that group testing was not used for the syphilis screenings. Most people are careful to say it was proposed and not used but without “closing the loop” people learning about it for the first time could be misled. Group testing has been used for many other diseases, most recently in some approaches for COVID screening.
The second example is randomized response, which is a technique for providing plausible deniability to survey respondents. A surveyer asks a sensitive binary question to an interviewee. The interviewee’s true answer is X∈{0,1}, samples a Bernoulli(p) random variable Z∈{0,1} (“flips a biased coin”) and responds with Y=X⊕Z where ⊕ is addition modulo 2. Randomized response was proposed by Stanley L. Warner in his 1965 JASA paper Randomized response: A survey technique for eliminating evasive answer bias. Talks on differential privacy (especially local differential privacy) often trot out Warner’s paper as an example of how differential privacy has appeared “classically.” I have done this myself.
Unfortunately, as a 2015 JASA paper of Blair, Imai, and Zhou notes:
Despite the wide applicability of the randomized response technique and the methodological advances, we find surprisingly few applications. Indeed, our extensive search yields only a handful of published studies that use the randomized response method to answer substantive questions…
The earliest study they could find was by Madigan et al. from 1976, who looked at a Misamis Oriental province in northern Mindanao (Philippines) and the prevalance of hiding deaths from official counts. So it seems randomized response was not implemented for around a decade after being proposed.
These examples show how easy it is to create misunderstandings by using anecdnotes about prior work in talks. I am certainly guilty of both misunderstanding the actual facts and perhaps misrepresenting what actually happened after these cool ideas were first proposed. We all know that the gap between theory and practice can be large, but somehow these fun stories make us a bit less careful.
 and compute the second moment matrix
and compute the second moment matrix  . If we want to compute the SVD in a differentially private way, one approach is to add noise
. If we want to compute the SVD in a differentially private way, one approach is to add noise  to the second moment matrix to form
to the second moment matrix to form 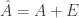 such that
such that 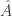 is a differentially private version of
is a differentially private version of  . Then by postprocessing invariance, the SVD of
. Then by postprocessing invariance, the SVD of  -differentially private algorithm? What is wrong with
-differentially private algorithm? What is wrong with  ? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the
? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the  choice for
choice for 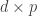 Gaussian matrix $\latex Z$ and settting
Gaussian matrix $\latex Z$ and settting  . This generates a PSD perturbation fo
. This generates a PSD perturbation fo 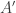 coming from neighboring databases, the cones are not the same. As a trivial example, suppose
coming from neighboring databases, the cones are not the same. As a trivial example, suppose 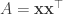 and
and  . Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive.
. Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive. is unacceptable.
is unacceptable. Wasserstein distance to measure the sensitivity of a function, and that adding noise that scales with this sensitivity would guarantee privacy in the Pufferfish model. She then gave an example for Bayesian networks and Markov chains. As we discussed, it seems like for each dependence structure you need to come up with a sort of covering of the dependencies to add noise appropriately. This seems pretty challenging in general now, but maybe after a bit more work there will be a clearer “general” strategy to handle dependence along these lines.
Wasserstein distance to measure the sensitivity of a function, and that adding noise that scales with this sensitivity would guarantee privacy in the Pufferfish model. She then gave an example for Bayesian networks and Markov chains. As we discussed, it seems like for each dependence structure you need to come up with a sort of covering of the dependencies to add noise appropriately. This seems pretty challenging in general now, but maybe after a bit more work there will be a clearer “general” strategy to handle dependence along these lines. individuals with data
individuals with data  representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction
representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction 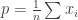 of users in the population. However, individuals don’t trust the surveyor. What to do?
of users in the population. However, individuals don’t trust the surveyor. What to do?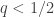 . The individual flips the coin in private. If it comes up heads, they lie and report
. The individual flips the coin in private. If it comes up heads, they lie and report  . If it comes up tails, they tell the truth
. If it comes up tails, they tell the truth  . The surveyor doesn’t see the outcome of the coin, but can compute the average of the
. The surveyor doesn’t see the outcome of the coin, but can compute the average of the  . What is the expected value of this average?
. What is the expected value of this average?![\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^{n} y_i \right] = \frac{1}{n} \sum_{i=1}^{n} (q (1 - x_i) + (1 -q) x_i) = q + (1 - 2q) p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+y_i+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%28q+%281+-+x_i%29+%2B+%281+-q%29+x_i%29+%3D+q+%2B+%281+-+2q%29+p&bg=ffffff&fg=333333&s=0&c=20201002) .
. : if we have a reported average
: if we have a reported average  then estimate
then estimate  .
.
 , we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of
, we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of  in terms of the “lying probability”
in terms of the “lying probability”  . We can plot this:
. We can plot this: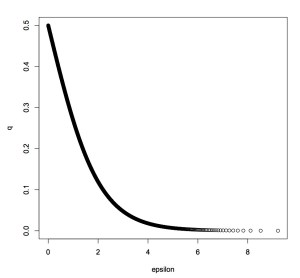
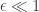 , but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.
, but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.