This is somewhat difficult to write, so I’ll cut to the chase. The proposed differentially private PCA method from the ICASSP 2016 paper by my student Hafiz Imtiaz and myself is incorrect and so should be retracted:
H. Imtiaz, A.D. Sarwate, Symmetric Matrix Perturbation for Differentially-Private Principal Component Analysis, Proceedings of the 2016 International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2339–2343, March 2016.
As a side-result, the paper of Jiang et al. from AAAI 2016 has as similar incorrect result. I’d like to thank my collaborator Kamalika Chaudhuri, who brought this up to me after a conversation with Kunal Talwar. The fact that I have taken so long to make this public announcement was due to a misguided effort to adapt the algorithm and run new experiments. Unfortunately, this was not to be.
What is the algorithm? Well, the basic idea in all of these papers is to add Wishart noise to produce a noisy estimate of the second-moment matrix of a data set. We start with some data vectors  and compute the second moment matrix
and compute the second moment matrix  . If we want to compute the SVD in a differentially private way, one approach is to add noise
. If we want to compute the SVD in a differentially private way, one approach is to add noise  to the second moment matrix to form
to the second moment matrix to form 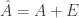 such that
such that 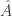 is a differentially private version of
is a differentially private version of  . Then by postprocessing invariance, the SVD of is also differentially private.
. Then by postprocessing invariance, the SVD of is also differentially private.
The motivation for our work was twofold: 1) we wanted to see how theoretically “optimal” algorithms performed on real data sets, especially for suggested settings of the parameters, and 2) we wanted to propose a good  -differentially private algorithm? What is wrong with
-differentially private algorithm? What is wrong with  ? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the , so they might not fly either. Plus, it’s a slightly more challenging and interesting mathematical problem.
? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the , so they might not fly either. Plus, it’s a slightly more challenging and interesting mathematical problem.
A very good  choice for is to choose the entries to be i.i.d. Gaussian on the diagonal and above and copy entries below the diagonal such that is symmetric. This is the Analyze Gauss (AG) algorithm of Dwork et al. Although is symmetric, it’s no longer positive semidefinite (PSD). However, this gives order-optimal guarantees on utility. Taking that as a cue, we wanted to preserve the PSD property in , so we proposed adding noise with a Wishart distribution, which corresponds to generating an i.i.d. rectangular
choice for is to choose the entries to be i.i.d. Gaussian on the diagonal and above and copy entries below the diagonal such that is symmetric. This is the Analyze Gauss (AG) algorithm of Dwork et al. Although is symmetric, it’s no longer positive semidefinite (PSD). However, this gives order-optimal guarantees on utility. Taking that as a cue, we wanted to preserve the PSD property in , so we proposed adding noise with a Wishart distribution, which corresponds to generating an i.i.d. rectangular 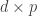 Gaussian matrix $\latex Z$ and settting
Gaussian matrix $\latex Z$ and settting  . This generates a PSD perturbation fo and has pretty good utility guarantees as well.
. This generates a PSD perturbation fo and has pretty good utility guarantees as well.
Unfortunately, the Wishart perturbation is blatantly non-private because the image under the perturbation is a PSD cone starting from , and for and 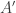 coming from neighboring databases, the cones are not the same. As a trivial example, suppose
coming from neighboring databases, the cones are not the same. As a trivial example, suppose 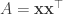 and
and  . Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive.
. Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive.
In the end, I was rather excited about the empirical performance (c.f. goal 1) above) and we were close to the deadline so I did not do a proper job checking the technical results in our rush to submit. I’m making this a teachable moment for myself but wanted to make sure there was a public, findable version of this retraction so that people don’t continue to build on our results. What we learned from 1) is that designing practical PCA methods for reasonable values of is still challenging — many data sets do not have the sample sizes needed to make differential privacy practical. The solution may be to design more complex multi-stage pipeline, revisit what we can assume about the data space and neighborhood relations, or come up with better algorithms that pass muster for the applications when nonzero  is unacceptable.
is unacceptable.
