IEEE Signal Processing Society
IEEE Transactions on Signal and Information Processing over Networks
Special Issue on Inference and Learning Over Networks
Networks are everywhere. They surround us at different levels and scales, whether we are dealing with communications networks, power grids, biological colonies, social networks, sensor networks, or distributed Big Data depositories. Therefore, it is not hard to appreciate the ongoing and steady progression of network science, a prolific research field spreading across many theoretical as well as applicative domains. Regardless of the particular context, the very essence of a network resides in the interaction among its individual constituents, and Nature itself offers beautiful paradigms thereof. Many biological networks and animal groups owe their sophistication to fairly structured patterns of cooperation, which are vital to their successful operation. While each individual agent is not capable of sophisticated behavior on its own, the combined interplay among simpler units and the distributed processing of dispersed pieces of information, enable the agents to solve complex tasks and enhance dramatically their performance. Self-organization, cooperation and adaptation emerge as the essential, combined attributes of a network tasked with distributed information processing, optimization, and inference. Such a network is conveniently described as an ensemble of spatially dispersed (possibly moving) agents, linked together through a (possibly time – varying) connection topology. The agents are allowed to interact locally and to perform in-network processing, in order to accomplish the assigned inferential task. Correspondingly, several problems such as, e.g., network intrusion, community detection, and disease outbreak inference, can be conveniently described by signals on graphs, where the graph typically accounts for the topology of the underlying space and we obtain multivariate observations associated with nodes/edges of the graph. The goal in these problems is to identify/infer/learn patterns of interest, including anomalies, outliers, and existence of latent communities. Unveiling the fundamental principles that govern distributed inference and learning over networks has been the common scope across a variety of disciplines, such as signal processing, machine learning, optimization, control, statistics, physics, economics, biology, computer, and social sciences. In the realm of signal processing, many new challenges have emerged, which stimulate research efforts toward delivering the theories and algorithms necessary to (a) designing networks with sophisticated inferential and learning abilities; (b) promoting truly distributed implementations, endowed with real-time adaptation abilities, needed to face the dynamical scenarios wherein real-world networks operate; and (c) discovering and disclosing significant relationships possibly hidden in the data collected from across networked systems and entities. This call for papers therefore encourages submissions from a broad range of experts that study such fundamental questions, including but not limited to:
- Adaptation and learning over networks.
- Consensus strategies; diffusion strategies.
- Distributed detection, estimation and filtering over networks.
- Distributed dictionary learning.
- Distributed game-theoretic learning.
- Distributed machine learning; online learning.
- Distributed optimization; stochastic approximation.
- Distributed proximal techniques, sub-gradient techniques.
- Learning over graphs; network tomography.
- Multi-agent coordination and processing over networks.
- Signal processing for biological, economic, and social networks.
- Signal processing over graphs.
Prospective authors should visit http://www.signalprocessingsociety.org/publications/periodicals/tsipn/ for information on paper submission. Manuscripts should be submitted via Manuscript Central at http://mc.manuscriptcentral.com/tsipn-ieee.
Important Dates:
- Manuscript submission: February 1, 2016
- First review completed: April 1, 2016
- Revised manuscript due: May 15, 2016
- Second review completed: July 15, 2016
- Final manuscript due: September 15, 2016
- Publication: December 1, 2016
Guest Editors:
- Vincenzo Matta, University of Salerno, Italy, vmatta@unisa.it
- Cédric Richard, University of Nice Sophia, Antipolis, France, cedric.richard@unice.fr
- Venkatesh Saligrama, Boston University, USA, srv@bu.edu
- Ali H. Sayed, University of California, Los Angeles, USA, sayed@ucla.edu
 individuals with data
individuals with data  representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction
representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction 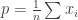 of users in the population. However, individuals don’t trust the surveyor. What to do?
of users in the population. However, individuals don’t trust the surveyor. What to do?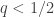 . The individual flips the coin in private. If it comes up heads, they lie and report
. The individual flips the coin in private. If it comes up heads, they lie and report  . If it comes up tails, they tell the truth
. If it comes up tails, they tell the truth  . The surveyor doesn’t see the outcome of the coin, but can compute the average of the
. The surveyor doesn’t see the outcome of the coin, but can compute the average of the  . What is the expected value of this average?
. What is the expected value of this average?![\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^{n} y_i \right] = \frac{1}{n} \sum_{i=1}^{n} (q (1 - x_i) + (1 -q) x_i) = q + (1 - 2q) p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+y_i+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%28q+%281+-+x_i%29+%2B+%281+-q%29+x_i%29+%3D+q+%2B+%281+-+2q%29+p&bg=ffffff&fg=333333&s=0&c=20201002) .
. : if we have a reported average
: if we have a reported average  then estimate
then estimate  .
.
 , we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of
, we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of  in terms of the “lying probability”
in terms of the “lying probability”  . We can plot this:
. We can plot this:
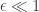 , but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.
, but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.