IEEE Signal Processing Society
IEEE Transactions on Signal and Information Processing over Networks
Special Issue on Distributed Information Processing in Social Networks
Over the past few decades, online social networks such as Facebook and Twitter have significantly changed the way people communicate and share information with each other. The opinion and behavior of each individual are heavily influenced through interacting with others. These local interactions lead to many interesting collective phenomena such as herding, consensus, and rumor spreading. At the same time, there is always the danger of mob mentality of following crowds, celebrities, or gurus who might provide misleading or even malicious information. Many efforts have been devoted to investigating the collective behavior in the context of various network topologies and the robustness of social networks in the presence of malicious threats. On the other hand, activities in social networks (clicks, searches, transactions, posts, and tweets) generate a massive amount of decentralized data, which is not only big in size but also complex in terms of its structure. Processing these data requires significant advances in accurate mathematical modeling and computationally efficient algorithm design. Many modern technological systems such as wireless sensor and robot networks are virtually the same as social networks in the sense that the nodes in both networks carry disparate information and communicate with constraints. Thus, investigating social networks will bring insightful principles on the system and algorithmic designs of many engineering networks. An example of such is the implementation of consensus algorithms for coordination and control in robot networks. Additionally, more and more research projects nowadays are data-driven. Social networks are natural sources of massive and diverse big data, which present unique opportunities and challenges to further develop theoretical data processing toolsets and investigate novel applications. This special issue aims to focus on addressing distributed information (signal, data, etc.) processing problems in social networks and also invites submissions from all other related disciplines to present comprehensive and diverse perspectives. Topics of interest include, but are not limited to:
- Dynamic social networks: time varying network topology, edge weights, etc.
- Social learning, distributed decision-making, estimation, and filtering
- Consensus and coordination in multi-agent networks
- Modeling and inference for information diffusion and rumor spreading
- Multi-layered social networks where social interactions take place at different scales or modalities
- Resource allocation, optimization, and control in multi-agent networks
- Modeling and strategic considerations for malicious behavior in networks
- Social media computing and networking
- Data mining, machine learning, and statistical inference frameworks and algorithms for handling big data from social networks
- Data-driven applications: attribution models for marketing and advertising, trend prediction, recommendation systems, crowdsourcing, etc.
- Other topics associated with social networks: graphical modeling, trust, privacy, engineering applications, etc.
Important Dates:
Manuscript submission due: September 15, 2016
First review completed: November 1, 2016
Revised manuscript due: December 15, 2016
Second review completed: February 1, 2017
Final manuscript due: March 15, 2017
Publication: June 1, 2017
Guest Editors:
Zhenliang Zhang, Qualcomm Corporate R&D (zhenlian@qti.qualcomm.com)
Wee Peng Tay, Nanyang Technological University (wptay@ntu.edu.sg)
Moez Draief, Imperial College London (m.draief@imperial.ac.uk)
Xiaodong Wang, Columbia University (xw2008@columbia.edu)
Edwin K. P. Chong, Colorado State University (edwin.chong@colostate.edu)
Alfred O. Hero III, University of Michigan (hero@eecs.umich.edu)
 and deterministic, rather than randomized, quantization. They consider two types — rounding and truncation (essentially the floor operation). The update rule is
and deterministic, rather than randomized, quantization. They consider two types — rounding and truncation (essentially the floor operation). The update rule is  where
where  is the quantization operation. They shoe that in finite time the agents either reach a consensus on the floor of the average of their initial values, or that the cycle indefinitely in a neighborhood around the average. They they show how to control the size of the neighborhood in a decentralized way. There are a lot of works on quantized consensus that have appeared in the last 5 years, and to be honest I haven’t really kept up on the recent literature, so I’m not sure how to compare this to the other works that have appeared, but perhaps some of the readers of the blog have…
is the quantization operation. They shoe that in finite time the agents either reach a consensus on the floor of the average of their initial values, or that the cycle indefinitely in a neighborhood around the average. They they show how to control the size of the neighborhood in a decentralized way. There are a lot of works on quantized consensus that have appeared in the last 5 years, and to be honest I haven’t really kept up on the recent literature, so I’m not sure how to compare this to the other works that have appeared, but perhaps some of the readers of the blog have…
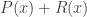 is strongly convex, the regularizer
is strongly convex, the regularizer 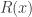 is lower semicontinuous and convex, and the term
is lower semicontinuous and convex, and the term 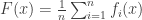 separates into a sum of function
separates into a sum of function  which are Lipschitz continuous. The proximal gradient method is an iterative procedure for solving this program that does the following:
which are Lipschitz continuous. The proximal gradient method is an iterative procedure for solving this program that does the following: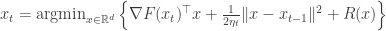
 function as
function as

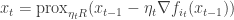
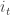 is sampled uniformly from
is sampled uniformly from 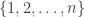 at each time. The advantage of the SG variant is that it takes less time to do one iteration, but each iteration is much noisier. The goal of this paper is to adapt a previous method/approach to variance reduction to improve the performance of the Prox-SG algorithm. The approach is one or resampling points according to the Lipschitz constants. This sort of “sampling based adaptivity” was also used by my ex-colleague
at each time. The advantage of the SG variant is that it takes less time to do one iteration, but each iteration is much noisier. The goal of this paper is to adapt a previous method/approach to variance reduction to improve the performance of the Prox-SG algorithm. The approach is one or resampling points according to the Lipschitz constants. This sort of “sampling based adaptivity” was also used by my ex-colleague  and at each time the learner picks an action
and at each time the learner picks an action  and observes an outcome
and observes an outcome  which is assigned a reward by a function
which is assigned a reward by a function  . The rewards are assumed to be i.i.d. across time for each action with distributions
. The rewards are assumed to be i.i.d. across time for each action with distributions 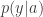 that are unknown to the learner. The goal is to maximize the reward, which is the same as finding the arm with the largest expected reward. This leads to a classical explore/exploit tradeoff where the learner has to decide whether to explore new arms which may have higher expected reward, or continue exploiting the reward offered by the current arm. Thompson sampling is a Bayesian approach where the learner starts with a prior on the best action and then samples actions at each time according to its posterior belief on the best arm. The authors here analyze the regret of such a policy in terms of what they call the information gain of the system. This gain depends on the ratio between two quantities that are functions of the outcome distributions
that are unknown to the learner. The goal is to maximize the reward, which is the same as finding the arm with the largest expected reward. This leads to a classical explore/exploit tradeoff where the learner has to decide whether to explore new arms which may have higher expected reward, or continue exploiting the reward offered by the current arm. Thompson sampling is a Bayesian approach where the learner starts with a prior on the best action and then samples actions at each time according to its posterior belief on the best arm. The authors here analyze the regret of such a policy in terms of what they call the information gain of the system. This gain depends on the ratio between two quantities that are functions of the outcome distributions  -dimensional data points
-dimensional data points ![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) the Lasso tries to fit the model
the Lasso tries to fit the model 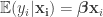 by minimizing the
by minimizing the 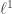 penalized squared error
penalized squared error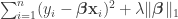 .
. i.i.d. copies of a pair of random variables
i.i.d. copies of a pair of random variables  so the data is
so the data is ![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The assumptions are on the random variables
. The assumptions are on the random variables 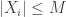 is bounded, the variable
is bounded, the variable  , and
, and  , where
, where  and
and  are unknown constants. Basically that’s all that’s needed — given a bound on
are unknown constants. Basically that’s all that’s needed — given a bound on  , he derives a bound on the mean-squared prediction error.
, he derives a bound on the mean-squared prediction error.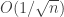 , can be improved to
, can be improved to  . Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic.
. Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic.
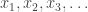 causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for
causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for  you need to take of a genome of of length
you need to take of a genome of of length  using reads of length
using reads of length  . It turns out that the correct scaling in this model is
. It turns out that the correct scaling in this model is  . Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still.
. Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still. and then do bootstrap estimates of size
and then do bootstrap estimates of size 