arXiv:1403.4696 [math.OC]
Design and Analysis of Distributed Averaging with Quantized Communication
Mahmoud El Chamie, Ji Liu, Tamer Başar
The goal of this paper is to analyze the “performance of a subclass of deterministic distributed averaging algorithms where the information exchange between neighboring nodes (agents) is subject to uniform quantization.” I was interested in the connections to Lavaei and Murray’s TAC paper. Here though, they consider a standard consensus setup with a doubly stochastic weight matrix  and deterministic, rather than randomized, quantization. They consider two types — rounding and truncation (essentially the floor operation). The update rule is
and deterministic, rather than randomized, quantization. They consider two types — rounding and truncation (essentially the floor operation). The update rule is  where
where  is the quantization operation. They shoe that in finite time the agents either reach a consensus on the floor of the average of their initial values, or that the cycle indefinitely in a neighborhood around the average. They they show how to control the size of the neighborhood in a decentralized way. There are a lot of works on quantized consensus that have appeared in the last 5 years, and to be honest I haven’t really kept up on the recent literature, so I’m not sure how to compare this to the other works that have appeared, but perhaps some of the readers of the blog have…
is the quantization operation. They shoe that in finite time the agents either reach a consensus on the floor of the average of their initial values, or that the cycle indefinitely in a neighborhood around the average. They they show how to control the size of the neighborhood in a decentralized way. There are a lot of works on quantized consensus that have appeared in the last 5 years, and to be honest I haven’t really kept up on the recent literature, so I’m not sure how to compare this to the other works that have appeared, but perhaps some of the readers of the blog have…
arXiv:1403.4699 [math.OC]
A Proximal Stochastic Gradient Method with Progressive Variance Reduction
Lin Xiao, Tong Zhang
This paper looks at convex optimization problems of the form

where the overall objective 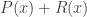 is strongly convex, the regularizer
is strongly convex, the regularizer 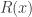 is lower semicontinuous and convex, and the term
is lower semicontinuous and convex, and the term 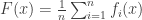 separates into a sum of function
separates into a sum of function  which are Lipschitz continuous. The proximal gradient method is an iterative procedure for solving this program that does the following:
which are Lipschitz continuous. The proximal gradient method is an iterative procedure for solving this program that does the following:
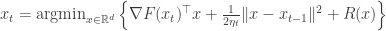
If we define the  function as
function as

then the step looks like:

A stochastic gradient (SG) version of this is
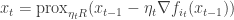
where 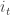 is sampled uniformly from
is sampled uniformly from 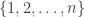 at each time. The advantage of the SG variant is that it takes less time to do one iteration, but each iteration is much noisier. The goal of this paper is to adapt a previous method/approach to variance reduction to improve the performance of the Prox-SG algorithm. The approach is one or resampling points according to the Lipschitz constants. This sort of “sampling based adaptivity” was also used by my ex-colleague Samory Kpotufe and collaborators in their NIPS paper from 2012 (a longer version is under review). At least I think they’re related.
at each time. The advantage of the SG variant is that it takes less time to do one iteration, but each iteration is much noisier. The goal of this paper is to adapt a previous method/approach to variance reduction to improve the performance of the Prox-SG algorithm. The approach is one or resampling points according to the Lipschitz constants. This sort of “sampling based adaptivity” was also used by my ex-colleague Samory Kpotufe and collaborators in their NIPS paper from 2012 (a longer version is under review). At least I think they’re related.
arXiv:1403.5341v1 [cs.LG]
An Information-Theoretic Analysis of Thompson Sampling
Daniel Russo, Benjamin Van Roy
In a multi-armed bandit problem we have a set of actions (arms)  and at each time the learner picks an action
and at each time the learner picks an action  and observes an outcome
and observes an outcome  which is assigned a reward by a function
which is assigned a reward by a function  . The rewards are assumed to be i.i.d. across time for each action with distributions
. The rewards are assumed to be i.i.d. across time for each action with distributions 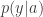 that are unknown to the learner. The goal is to maximize the reward, which is the same as finding the arm with the largest expected reward. This leads to a classical explore/exploit tradeoff where the learner has to decide whether to explore new arms which may have higher expected reward, or continue exploiting the reward offered by the current arm. Thompson sampling is a Bayesian approach where the learner starts with a prior on the best action and then samples actions at each time according to its posterior belief on the best arm. The authors here analyze the regret of such a policy in terms of what they call the information gain of the system. This gain depends on the ratio between two quantities that are functions of the outcome distributions . One is what they call the “divergence in mean,” namely the difference in expected reward between arms, and the other is the KL divergence.
that are unknown to the learner. The goal is to maximize the reward, which is the same as finding the arm with the largest expected reward. This leads to a classical explore/exploit tradeoff where the learner has to decide whether to explore new arms which may have higher expected reward, or continue exploiting the reward offered by the current arm. Thompson sampling is a Bayesian approach where the learner starts with a prior on the best action and then samples actions at each time according to its posterior belief on the best arm. The authors here analyze the regret of such a policy in terms of what they call the information gain of the system. This gain depends on the ratio between two quantities that are functions of the outcome distributions . One is what they call the “divergence in mean,” namely the difference in expected reward between arms, and the other is the KL divergence.
