IEEE Journal of Selected Topics in Signal Processing
IEEE Transactions on Signal and Information Processing over Networks
Special Issues on Graph Signal Processing
Numerous applications rely on the processing of high-dimensional data that resides on irregular or otherwise unordered structures which are naturally modeled as networks (such as social, economic, energy, transportation, telecommunication, sensor, and neural, to name a few). The need for new tools to process such data has led to the emergence of the field of graph signal processing, which merges algebraic and spectral graph theoretic concepts with computational harmonic analysis to process signals on structures such as graphs. This important new paradigm in signal processing research, coupled with its numerous applications in very different domains, has fueled the rapid development of an inter-disciplinary research community that has been working on theoretical aspects of graph signal processing and applications to diverse problems such as big data analysis, coding and compression of 3D point clouds, biological data processing, and brain network analysis.
The purpose of these special issues is to gather the latest advances in graph signal processing and disseminate new ideas and experiences in this emerging field to a broad audience. We encourage the submission of papers with new results, methods or applications in graph signal processing. In particular, the topics of interest include (but are not limited to):
- Sampling and recovery of graph signals
- Graph filter and filter bank design
- Uncertainty principles and other fundamental limits
- Graph signal transforms
- Graph topology inference
- Prediction and learning in graphs
- Statistical graph signal processing
- Non-linear graph signal processing
- Applications to visual information processing
- Applications to neuroscience and other medical fields
- Applications to economics and social networks
- Applications to various infrastructure networks
Submission Procedure:
Prospective authors should follow the instructions given on the IEEE JSTSP webpages and submit their manuscript with the web submission system at https://mc.manuscriptcentral.com/jstsp-ieee. The decisions on whether the accepted papers will be published in IEEE JSTSP or IEEE TSIPN will depend on the respective themes of the papers and will be made by the Guest Editors.
Schedule (all deadlines are firm):
Manuscript due: Nov 1, 2016
First Review Completed: Jan 1, 2017
Revised manuscript due: Mar 1, 2017
Second Review Completed: May 1, 2017
Final manuscript due: June 1, 2017
Publication date: September 2017
Guest Editors:
- Pier-Luigi Dragotti, Imperial College, London (p.dragotti@imperial.ac.uk)
- Pascal Frossard, EPFL, Lausanne (pascal.frossard@epfl.ch)
- Antonio Ortega, USC, Los Angeles (ortega@sipi.usc.edu)
- Michael Rabbat, McGill University, Montreal (michael.rabbat@mcgill.ca)
- Alejandro Ribeiro, UPenn, Philadelphia (aribeiro@seas.upenn.edu)
 of
of  of size
of size 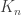 at each node. The subset is the set of keys available at each node; two nodes can talk (securely) if they share a key in common. We keep the edge in the RGG is if the link can be secured. The question is whether the secure-link graph is connected. It turns out that the important scaling is in terms of
at each node. The subset is the set of keys available at each node; two nodes can talk (securely) if they share a key in common. We keep the edge in the RGG is if the link can be secured. The question is whether the secure-link graph is connected. It turns out that the important scaling is in terms of  , where
, where 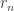 is the connectivity radius of the RGG. This sort of makes sense, as the threshold is more or less
is the connectivity radius of the RGG. This sort of makes sense, as the threshold is more or less 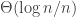 , so the keys provide a kind of discount factor on effective radius needed for connectivity — if the number of keys per node is small then you need a larger radius to compensate.
, so the keys provide a kind of discount factor on effective radius needed for connectivity — if the number of keys per node is small then you need a larger radius to compensate. shares of a secret such that any
shares of a secret such that any  of them can be used to reconstruct the secret but
of them can be used to reconstruct the secret but  or fewer cannot. The idea here is that the dealer has to distribute these shares over the network, which means that if a receiver is not connected directly to the dealer then the share will be passed insecurely through another node. Existing approaches based on pairwise agreement protocols are communication intensive. The idea here is use ideas from network coding to share masked versions of shares so that intermediate nodes will not get valid shares from others. To do this the graph needs to satisfy a particular condition (
or fewer cannot. The idea here is that the dealer has to distribute these shares over the network, which means that if a receiver is not connected directly to the dealer then the share will be passed insecurely through another node. Existing approaches based on pairwise agreement protocols are communication intensive. The idea here is use ideas from network coding to share masked versions of shares so that intermediate nodes will not get valid shares from others. To do this the graph needs to satisfy a particular condition (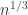 where
where 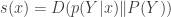 where
where  and
and  are the input and output of the channel. He gets a single-letter expression for the capacity under a bound on the max surprise and gives an example for which the same distribuion maximizes mutual information and achieves the minimax surprise. The flip side is to ask for capacity when each output should be surprising (or “attention seeking”). He gets a single letter capacity here as well, but the structure of the solution seems to be a bit more complicated.
are the input and output of the channel. He gets a single-letter expression for the capacity under a bound on the max surprise and gives an example for which the same distribuion maximizes mutual information and achieves the minimax surprise. The flip side is to ask for capacity when each output should be surprising (or “attention seeking”). He gets a single letter capacity here as well, but the structure of the solution seems to be a bit more complicated.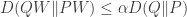
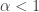 , so the idea is to get bounds on
, so the idea is to get bounds on .
.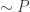 from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item
from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item  . This paper looks at the number of guesses one needs if
. This paper looks at the number of guesses one needs if  is uniform on the typical set according to
is uniform on the typical set according to 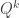 conditioned on
conditioned on 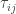 for the
for the  to infect
to infect  if
if 