Again a caveat — these are the talks in which I took reasonable enough notes to write anything coherent.
Green Communication: From Maxwell’s Demon to “Informational Friction”
Pulkit Grover
Pulkit talked about trying to tie a physical interpretation the energy used in communication during computation. Physicists might argue that reversible computation costs nothing, but this ignores friction and noise. Pulkit discussed a simple network model to account for “informational friction” that penalizes the bit-distance product in communicating on a chip. See also Pulkit’s short video on the topic.
Energy Harvesting Receivers
Hajar Mahdavi-Doost, Roy Yates
Roy talked about a model in which receivers have to harvest the energy they need for sampling/buffering/decoding the transmissions. These three tasks cost different amounts, and in particular, the rate at which the receiver samples the output dictates the other parameters. The goal is to choose a rate which helps meet the decoder energy requirements. Because the receiver has to harvest the energy it needs, it has to design a policy to switch between the three operations while harvesting the (time-varying) energy available to it.
Multiple Access and Two-way Channels with Energy Harvesting and Bidirectional Energy Cooperation
Kaya Tutuncuoglu Aylin Yener
Unlike the previous talk, this was about encoders which have to transmit energy to the receivers — there’s a tradeoff between transmitting data and energy, and in the MAC and TWC there is yet another dimension in how the two users can cooperate. For eample, they can cooperate in energy transmission but not data cooperation. There were a lot of results in here, but there was also a discussion of policies for the users. In particular a “procrastination” strategy turns out to work well (rejoice!).
An equivalence between network coding and index coding
Michelle Effros, Salim El Rouayheb, Michael Langberg
The title says it all! For every network coding problem (multiple unicast, multicast, whatever), there exists a corresponding index coding problem (constructed via a reduction) such that a solution to the latter can be easily translated to a solution for the former. This equivalence holds for all network coding problems, not just linear ones.
Crowd-sourcing epidemic detection
Constantine Caramanis, Chris Milling, Shie Mannor, Sanjay Shakkottai
Suppose we have a graph and we can see some nodes are infected. This paper was on trying to distinguish between whether the infected nodes started from a single point infection spread via an SI model, or just from a random pattern of infection. They provide two algorithms for doing this and then address how to deal with false positives using ideas from robust statistics.
 different “sources” or states being observed through a channel which looked like a AWGN faded interference channel, where the fading represents the relative influence of the source (or load on the network) on the receiver (or ISO). She didn’t quite have time to go into the second model, which was more at the level of individual homes, where short-time-scale monitoring of loading can reveal pretty much all the details of what’s going on in a house. The talk was a summary of some recent papers available on her website.
different “sources” or states being observed through a channel which looked like a AWGN faded interference channel, where the fading represents the relative influence of the source (or load on the network) on the receiver (or ISO). She didn’t quite have time to go into the second model, which was more at the level of individual homes, where short-time-scale monitoring of loading can reveal pretty much all the details of what’s going on in a house. The talk was a summary of some recent papers available on her website. where the different elements of the state are related via a graph matched to
where the different elements of the state are related via a graph matched to  and you want the input
and you want the input  to only be nonzero on a subset of the nodes. Thanks to Ann Wehman for the pointer.
to only be nonzero on a subset of the nodes. Thanks to Ann Wehman for the pointer.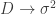 (for the Gaussian case).
(for the Gaussian case). . Maybe we can make a YouTube channel for them.
. Maybe we can make a YouTube channel for them.