here are the four posts I made on the strong converse for the MAC:
- Part 1 : the setup and Fano distributions
- Part 2 : choosing a non-product subcode
- Part 3 : a wringing lemma
- Part 4 : almost-independence via wringing
Thanks for reading!
In the previous post we saw how to take two distributions 

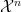


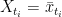
Corollary 1 Let
and suppose
and let
be a code for the MAC with maximal error probability
. Then for an
and
there exist
for
and fixed values
such that the subcode formed by
has maximal error
and for all
and
and all
,
where
and
are distributed according to the Fano distribution of the subcode.
That is, we can condition on some values at 

So how does this result follow from the Wringing Lemma discussed before? Let
Then just churn through the implications of the Lemma.
So putting the whole argument together, we start first with an 
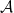




There are three steps here — first you find a subcode with more uniform error properties but dependence between the codewords, then you wring out the dependence without giving up too much rate, and finally you substitute in the independent inputs without giving up too much rate. And that’s the value of wringing arguments: in order to get the nice structure from the subcode with
Academicians! Here’s a topic for discussion. To what degree is this characterization true? (h/t LDC)
Now that I am not traveling around as much and stressed out about job decisions, I have gotten back to cooking. I miss my mother’s cooking and frequently call home to check on recipes (to the point where my mother’s first question is sometimes “what do you want to cook today?”). I figured I’d post some recipes here occasionally. This recipe is for Patal Bhaji, a Maharashtrian comfort dish. Although there are a lot of ingredients, most of them are “pantry items,” at least in Indian kitchens.
Alas there are no pictures because it’s been eaten. I made the variety with chana dal because I seem to have a metric ton of chana dal at my apartment.
This post was written using Luca’s LATEX2WP tool.
The topic of this (late) post is “wringing” techniques, which are a way of converting a statement like “



Lemma 1 Let
such that for a positive constant
,
then for any
and
there exist
, where
such that for some
,
for all
and all
. Furthermore,
The proof works pretty mechanically. Fix a 


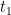

where the first bound is from the assumption and the second because the conclusion doesn’t hold. Then we have 


Now, either the conclusion is true or we use (2) in place of (1) to find a 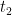

We can keep going in this way until we get 

Rather than describe how to apply this to our coding problem, I want to contrast this rather simple statement to the other wringing lemma in the paper, which is a generalization of the lemma developed by Dueck. This one is more “information theoretic” in the sense that it says if the block mutual information is small, then we can find positions to condition on such that the per-letter mutual informations are small too.
Lemma 2 Let
and
be
-tuples of random variables from discrete finite alphabets
and assume that
Then for any
and there exist
such that for some
,
for all
This lemma proved in basically the same way as the previous lemma, but it’s a bit messier. Dueck’s original version was the similar but gave a bound on the conditional mutual information, rather than this bound where we condition on particular values. This way of taking a small mutual information and getting small per-letter mutual informations can be useful outside of this particular problem, I imagine.
Next time I’ll show how to apply the first lemma to our codebooks in the converse for the MAC.
Kenji explains the science of no-knead bread. I have to try making some this summer.
A nice post about Punjabi Mexicans in California, a little-known bit of South Asian immigration history in the US.
Detection of correlations is a snazzy title, but they mean something very particular by it. Also, why does everyone hate on the GLRT so much?
I want to see The Trip, especially after watching this clip. (h/t Adam G.)
P. Sainath on civil society in India. (h/t Soumya C.)
I seem to given the wrong impression (probably due to grumpiness) in the previous post about my views on the value of reviewing. I actually enjoy reviewing – I get a sneak preview of new results and techniques through the review process, and there are often many interesting tidbits. My perspective is skewed by the IEEE Transactions on Information Theory, which has a notoriously lengthy review process. For example, it took 15 months for me to get two reviews of a manuscript that I submitted. One of the top priorities for the IT Society has been to get the time from submission to publication down to something reasonable. That’s the motivation for my question about incentives for timely reviewing. So why should you submit a timely review?
Reviewing is service. Firstly, it’s your obligation to review papers if you submit papers. Furthermore, you should do it quickly because you would like your reviews quickly. This seems pretty fair.
Reviewing builds your reputation. There is the claim that you build reputation by submitting timely and thorough reviews. I think this is a much weaker claim — this reputation is not public, which is an issue that was raised in the paper by Parv and Anant that I linked to earlier. It’s true that the editorial board might talk about how you’re a good reviewer and that later on down the line, an Associate Editor for whom you did a fair bit of work may be asked to write you a tenure letter, but this is all a bit intangible. I’ve reviewed for editors whom I have never met and likely never will meet.
Doing a good review on time is its own reward. This is certainly true. As I said, I have learned a ton from reviewing papers and it has also helped me improve my own writing. Plus, as Rif mentioned, you can feel satisfied that you were true to your word and did a good job.
Isn’t all of this enough? Apparently not. There are a lot of additional factors which make these benefits “not enough.” Firstly, doing service for your intellectual community is good, but this takes you as far as “you should accept reviews if the paper seems relevant and you would be a good reviewer.” I don’t think the big problem is freeloading; people accept reviews but then miss lots of deadlines. Most people don’t bother to say “no” when asked to do a review, leaving the AE (or TPC member) in limbo. There needs to be a way to make saying “no” acceptable and obligatory.
The real issue with reputation-building is that it’s a slow process; the incentive to review a particular paper now is both incremental and non-immediate. One way out would be to hold submitted papers hostage until the authors review another paper, but that is a terrible idea. There should be a way for reviewers to benefit more immediately from going a good and timely job. Cash payouts are probably not the best option…
Finally, the self-satisfaction of doing a good job is a smaller-scale benefit than those from other activities. It is the sad truth that many submitted manuscripts are a real chore to review. These papers languish in the reviewer’s stack because working up the energy to review them is hard and because doing the review doesn’t seem nearly as important as other things, like finishing your own paper, or that grant proposal, etc. The longer a paper sits gathering dust on the corner of your desk, the less likely you are to pick it up. I bet that much more than half the reviews are not even started until the Associate Editor sends an email reminder.
It takes a fair bit of time to review a 47 page 1.5-spaced mathematically dense manuscript, and to do it right you often need to allocate several contiguous chunks of time. These rare gems often seem better spent on writing grant proposals or doing your own research. The rewards for those activities are much more immediate and beneficial than the (secret) approval and (self-awarded) congratulations you will get for writing a really helpful review. The benefits for doing a good timely review are not on the same order as other activities competing for one’s time.
I guess the upshot is that trusting the research community to make itself efficient at providing timely and thorough reviews may not be enough. Finding an appropriate solution or intervention requires looking at some data. What is the distribution of review times? (Cue power-law brou-ha-ha). What fraction of contacted reviewers fail to respond? What fraction of reviewers accept? For each paper, how does length/quality of review correlate with delay? Knowing things like this might help get things back up to speed.
I know I complain about this all the time, but in my post-job-hunt effort to get back on top of things, I’ve been trying to manage my review stack.
It is unclear to me what the reward for submitting a review on time is. If you submit a review on time, the AE knows that you are a reliable reviewer and will ask you to review more things in the future. So you’ve just increased your reviewing load. This certainly doesn’t help you get your own work done, since you end up spending more time reviewing papers. Furthermore, there’s something disheartening about submitting a review and then a few months later getting BCC-ed on the editorial decision. Of course, reviewing can be its own reward; I’ve learned a lot from some papers. It struck me today that there’s no real incentive to get the review in on time. Parv and Anant may be on to something here (alternate link).
I have accepted an offer to join the Toyota Technological Institute at Chicago this fall as a Research Assistant Professor. I’m excited by all of the opportunities there; it’s a great chance to dig deeper into some exciting research problems while learning a lot of new things from the great people they have there. It’s in Hyde Park, which is a great stepping stone for future career opportunities…
Robert Tavernor, Smoot’s Ear : The Measure of Humanity – This is an interesting, albeit dry, history of measurement in Europe, starting from the Greeks and Romans, more or less, up through the development of the metric system. It’s chock full of interesting little facts and also highlights the real problems that arise when there is no standard as well as when trying to define a standard.
Naguib Mahfouz, Palace Walk – The first in Mahfouz’s masterpiece trilogy, this novel follows a very traditional family of an Egyptian merchant, who spends his time partying every night while terrorizing his family during the day. It’s set during the end of the British occupation at the end of WWI and the protests against the British that start at the end of the novel seem eerily relevant today.
Nell Irvin Painter, The History of White People – This is a popular history of theories of race, beauty, and intelligence and how they became entwined with skin color, head-shape, and other measurable quantities. It was an interesting read but felt a little incomplete somehow. Also, she uses the work “pride of place” too many times. It was distracting!
Vivek Borkar, Stochastic Approximation : a Dynamical Systems Viewpoint – This slim book gives a concise, albeit very technical, introduction to the basic methods and results in stochastic approximation. It’s fairly mathematically challenging, but because it’s to-the-point, I found it easier going than the book by Kushner and Yin.













{kind=link}