here are the four posts I made on the strong converse for the MAC:
- Part 1 : the setup and Fano distributions
- Part 2 : choosing a non-product subcode
- Part 3 : a wringing lemma
- Part 4 : almost-independence via wringing
Thanks for reading!
In the previous post we saw how to take two distributions 

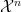


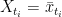
Corollary 1 Let
and suppose
and let
be a code for the MAC with maximal error probability
. Then for an
and
there exist
for
and fixed values
such that the subcode formed by
has maximal error
and for all
and
and all
,
where
and
are distributed according to the Fano distribution of the subcode.
That is, we can condition on some values at 

So how does this result follow from the Wringing Lemma discussed before? Let
Then just churn through the implications of the Lemma.
So putting the whole argument together, we start first with an 
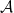




There are three steps here — first you find a subcode with more uniform error properties but dependence between the codewords, then you wring out the dependence without giving up too much rate, and finally you substitute in the independent inputs without giving up too much rate. And that’s the value of wringing arguments: in order to get the nice structure from the subcode with




