Konnichiwa, Varshney-san. Your post on the potato inspired me to read the papers you mentioned as well as a reference suggested by a friend here in Chicago:
Sucheta Mazumdar, “The Impact of New World Food Crops on the Diet and Economy of China and India, ca. 1600-1900.” Food in Global History. Ed. Raymond Grew. Westview Press, 1999. 58-78.
The Columbian Exchange refers to the interchange of foodstuffs, technologies, and disease after European contact with the Americas. In exchange for offering pestilence, brutal colonialism, and genocide, Europeans got a variety of staple crops with which they could support their burgeoning populations and which would later sustain the Industrial Revolution:
The exchange introduced a wide range of new calorically rich staple crops to the Old World—namely potatoes, sweet potatoes, maize, and cassava. The primary benefifit of the New World staples was that they could be grown in Old World climates that were unsuitable for the cultivation of Old World staples. (Nunn and Qian)
In addition, the discovery of quinine in the Andes enabled Europeans to invade and colonize tropical regions. In addition to the trans-Atlantic slave trade, this expansion introduced the widespread planting of cash crops such as rubber in Africa. Being an economics paper, there are some sobering quantitative measures to drive home the horrors of colonial exploitation:
The population of the Congo is estimated to have been about 25 million prior the rubber boom, in the 1880s. In 1911, after the peak of the boom, the population was 8.5 million, and in 1923 after the completion of the boom, it was 7.7 million. If one compares the population losses relative to the production of rubber, an astonishing conclusion is reached: an individual was “lost” from the Congo for every ten kilograms of rubber exported (Loadman, 2005, pp. 140–41).
The potato paper covers the effect of potatoes and tries to estimate (numerically) the impact potato cultivation had on population growth and urbanization in Europe. It is somewhat elusive to me what such a quantification “means,” but it’s of a piece with what Ian Hacking describes in The Taming of Chance : the torrent of printed numbers led to the publication of attendant “studies” slicing and dicing the numbers in statistical ways in order to “make sense” of them. The second Nunn and Qian paper covers capsicum, tomatoes, cacao, vanilla, coca, and tobacco, and contains some fun nutritional facts and trivia:
- Capsicum is high in vitamins A, B and C, magnesium, and iron, and the extra saliva produced by capsacin helps digestion.
- “Greece consumes the most tomatoes per capita… The tomato has been so thoroughly adopted and integrated into Western diets that today it provides more nutrients and vitamins than any other fruit or vegetable (Sokolov, 1993, p. 108).”
- “[I]n Roald Amundsen’s trek to the South Pole, his men were allocated 4,560 calories per day, of which over 1,000 came from cacao (West, 1992, pp. 117–18).”
My interest came more from vegetables that almost define Indian cuisine : tomatoes, potatoes, and chilies. Mazumdar’s article focuses on the effect new crops had on China and India. Specific to this context,
There were two major periods of introduction of American plants into Asia. The first wave, in the sixteenth and seventeeth centuries, included sweet potatoes, maize, potatoes, jicamas, capsicums (chile peppers), squashes, and peanuts, cashews, custard apples, guavas, avocadoes, tomatoes, papaya, passion-fruit, pineapples, and sapodillas… In the second wave, American plants, such as cocoa and the sunflower, were brought to India even more recently in the twentieth century.
With them came new words of course — South Asian readers may know of a certain fruit as sapota (in the south) or chiku (in the north), both of which come from a Meso-American word (not sure of the language) chicosapote. The word achar for pickles came from the Carib axi meaning chile pepper.
The paper draws a distinction between how land ownership practices in India and China made a difference in how fast new foods were incorporated into the common diet. In China, a number of reforms allowed “tenancy rights to become inheritable” for peasants, meaning they had an incentive to say in place and try to extract more productivity from the land they had. The new crops, especially the sweet potato, became staples because they provided more calories per acre, and because they were drought- and pest-resistant, required less labor (especially over rice), and could grow in poor soil. Mazumdar writes:
[In the 1920s in south China] sweet potatoes regularly provided a supply of at least three to four months’ worth or food for practically everybody living in the countryside… they were eaten fresh, baked, boiled, or mashed with pickles.. ground into flour and made into noodles, bread, or a gruel… or stirred into a hash.
The sweet potato revolutionized the lives of peasants in China, giving them more calories and freeing time and labor to grow cash crops. Corn and peanuts were also widely cultivated, since corn could also grow in nutrient-poor soils and peanuts are good nitrogen-fixers and could be grown with sugarcane.
India was a different story — there was more arable land and “relatively low population growth between 1600 and 1850.” Due to military conflicts and tensions with zamindars (landlords), villages would often up and leave, transplanting themselves further from conflict or interference. This meant that unlike China, rural farmers were not as tied to specific locations during this period. Colonialism changed all that — people were pinned down and agriculture was commercialized, so in the 19th and 20th centuries American crops started flourishing. The Brits promoted the potato heavily, and increased urbanization brought it and the tomato into the mainstream. Although it’s hard to think of Indian food without tomatoes, potatoes, and chilies, these ingredients were only integrated around 150 years ago!
 scalars
scalars ![x_i \in [0,1]](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and we want to compute the average
and we want to compute the average 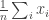 in a differentially private way. One way to do this is to release
in a differentially private way. One way to do this is to release 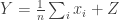 , where
, where  has a Laplace distribution:
has a Laplace distribution: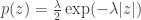 .
. the average can change by at most
the average can change by at most  . Let
. Let 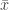 and
and  be the average of the original data and the data with one element changed. The output density in these two cases has distribution
be the average of the original data and the data with one element changed. The output density in these two cases has distribution  and
and  , so for a
, so for a 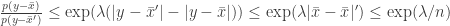
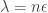 we get an
we get an  -differentially private approximation to the average.
-differentially private approximation to the average.![\mathbf{x}_i \in [0,1]^d](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D_i+%5Cin+%5B0%2C1%5D%5Ed&bg=ffffff&fg=333333&s=0&c=20201002) ? Well, one candidate is release a differentially private version of the mean by computing
? Well, one candidate is release a differentially private version of the mean by computing  , where
, where  has a distribution that looks Laplace-like but in higher dimensions:
has a distribution that looks Laplace-like but in higher dimensions:
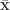 and
and 
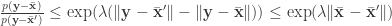
 (by replacing
(by replacing  with
with  , for example), so the overall bound is
, for example), so the overall bound is  , which means choosing
, which means choosing  we get
we get 
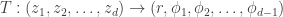 whose Jacobian is
whose Jacobian is .
.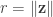 we get
we get .
.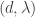 . We can generate this by taking the sum of
. We can generate this by taking the sum of  exponential variables with parameter
exponential variables with parameter  . The direction we can pick uniformly by sampling
. The direction we can pick uniformly by sampling  , there is a convex probability distribution
, there is a convex probability distribution  on the real line with a finite entropy, such that
on the real line with a finite entropy, such that  , where
, where  and
and  are independent random variables, distributed according to
are independent random variables, distributed according to 
