Maybe more like “paper whenever I feel like it.” This is a post on a now not-so-recent ArXiV preprint by Quan Geng and Pramod Viswanath on constructing the best mechanism (output distribution) for guaranteeing differential privacy under a utility constraint.
For those readers not quite familiar with differential privacy, the setup may seem a little enigmatic. The idea is that there are 
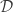



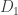
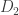
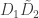
.
Since the log likelihood ratio is small, the hypothesis test is difficult, and an adversary would have a hard time inferring any individual’s data, even if the other data points are revealed. I’m being a bit loose here and saying that the output has a density but you can undo the logs and so on to get a better statement:
.
for any measurable set 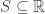

The focus of the paper is on questioning the ubiquity of the Laplace distribution in guaranteeing differential privacy. In particular, given a real-valued query function 
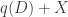


More formally, they consider mechanisms of the form
,
where 


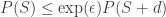
for all measurable 


So this really boils down to a constrained optimization program reminiscent of those we sometimes find in information theory, like finding the capacity achieving input distribution.
The main point of the paper is that the optimal distribution is not Laplace, but staircase-shaped:
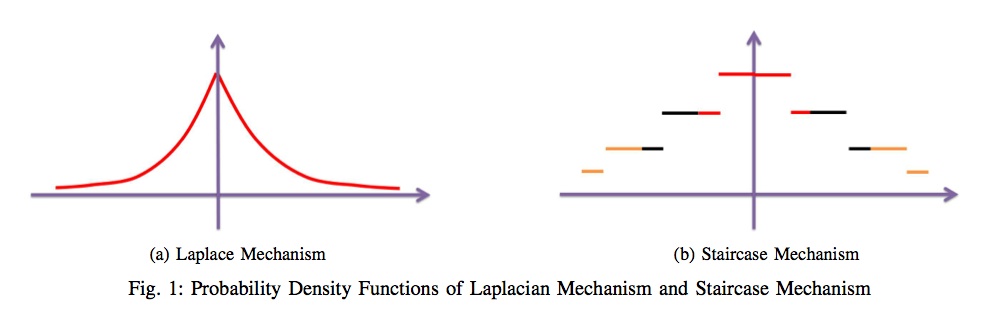
Laplace and staircase densities
And that as
 the Laplace distribution does become optimal, whereas as
the Laplace distribution does become optimal, whereas as 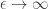 it is not. Since choosing an appropriate in practical settings is an open question, the “moderate” regime is interesting.
it is not. Since choosing an appropriate in practical settings is an open question, the “moderate” regime is interesting.
How does one prove this result? Basically you have to show that the optimum distribution satisfies various properties. They also need to assume that the cost function is symmetric (not always the case, but usually true) and that it cannot increase too quickly (which is reasonable in many cases). The main approach is to take any differentially private output density and instead look at piecewise constant densities as approximations. This is noncontroversial — the same trick is used in functional analysis. The real key insight is that the steps are of width 
There are more extensions and examples in the paper, but it’s worth a skim if you have a passing interest in differentially private mechanisms and a deeper read if you want to get some insights into what kind of constraints differential privacy puts on output distributions.

Very nice and interesting. Thanks for sharing. The staircase noise distribution seems like a quantized Laplacian at first shot — must be a property of the utility function desired. I have always wondered why Laplacian (after all, we IT folks know that additive noise is not necessarily optimal for a large class of sources) but then since the source statistics is swept under the carpet in DP, finding the optimal input-to-output distribution needs to satisfy other criterion and maybe then linear noise models suffice.
Pingback: Generating vector-valued noise for differential privacy | An Ergodic Walk