A distribution that appears frequently in differential privacy is the Laplace distribution. While in the scalar case we have seen that Laplace noise may not be the best, it’s still the easiest example to start with. Suppose we have 
![x_i \in [0,1]](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
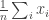
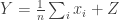

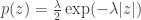
To see that this is differentially private, note that by changing one value of 

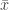



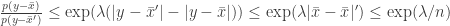
So we can see by choosing 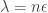

What if we now have n vectors ![\mathbf{x}_i \in [0,1]^d](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D_i+%5Cin+%5B0%2C1%5D%5Ed&bg=ffffff&fg=333333&s=0&c=20201002)



Now we can do the same calculation with means 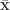

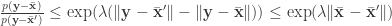
Now the Euclidean norm of the average vector can change by a most 




Sampling from exponentials is easy, but what about sampling from this distribution? Here’s where people can fall into a trap because they are not careful about transformations of random variables. It’s tempting (if you are rusty on your probability) to say that

and then say “well, the norm looks exponentially distributed and the direction is isotropic so we can just sample the norm with an exponential distribution and the uniform direction by taking i.i.d. Gaussians and normalizing them.” But that’s totally wrong because that is implicitly doing a change of variables without properly adjusting the density function. The correct thing to do is to change from Euclidean coordinates to spherical coordinates. We have a map 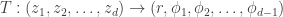

Plugging this in and noting that 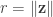

So now we can see that the distribution factorizes and indeed the radius and direction are independent. The radius is not exponentially distributed, it’s Erlang with parameters 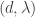


In general sampling distributions for differentially private mechanisms can be complicated — for example in our work on PCA we had to use an MCMC procedure in our experiments to sample from the distribution in our algorithm. This means we could really only approximate our algorithm in the experiments, of course. There are also places to slip up in sampling from simple-looking distributions, and I’d be willing to bet that in some implementations out there people are not sampling from the correct distribution.
(Thanks to Kamalika Chaudhuri for inspiring this post.)
