Namely, that continuous variables have infinite entropy and common randomness can be very useful : Unlimited data transmission with only TWO NUMBERS, baby!
Monthly Archives: November 2011
The linguistic diversity of mustard seeds
From Thangam Philip’s book Modern Cookery:
Mustard seeds (Brassica nigra) :
Hindi – rai
Tamil – kadugu
Telugu – avalu
Kannada – sasuve
Oriya – sorisa
Marathi – mohori
Bengali – sorse
Gujarati – rai
Malayalam – kadugu
Kashmiri – aasur
A recent discussion with Lalitha Sankar and Prasad Santhanam brought up this linguistic diversity. Clearly sorse/sasuve/sorisa/ come from the same root as sarson, which are mustard greens. Maybe aasur is derived from that as well, but where do the others come from?
It turns out that the Farsi word is خردل, or khardal (thanks to Amin Mobasher for the help), which is probably the source for the Tamil/Malayalam.
But, much to my chagrin as a Maharashtrian, I do not know the origins of mohori, nor do I have any in my kitchen right now (soon to be rectified by a trip to Devon)!
Not really the digital divide
I started my new job here at TTI Chicago this fall and I’ve been enjoying the fact that TTI is partnered up with the University of Chicago — I get access to the library, and a slightly better rate at the gym (still got to get on that), and some other perks. However, U of C doesn’t have an engineering school. So the library has a pretty minimal subscription to IEEExplore. Which leaves me in a bit of predicament — I’m a member of some of the IEEE societies, so I can get access to those Transactions, but otherwise I have to work a bit harder to get access to some papers. So far it hasn’t proved to be problem, but I think I might run into a situation like the one recently mentioned by David Eppstein.
A creepy but prescient quote
… statistical research accompanies the individual through his entire earthly existence. It takes account of his birth, his baptism, his vaccination, his schooling and the success thereof, his diligence, his leave of school, his subsequent education and development; and, once he becomes a man, his physique and his ability to bear arms. It also accompanies the subsequent steps of his walk through life; it takes note of his chosen occupation, where he sets up his household and his management of the same; if he saved from the abundance of his youth for his old age, if and when and at what age he marries and who he chooses as his wife — statistics looks after him when things go well for him and when they go awry. Should he suffer a shipwreck in his life, undergo material, moral or spiritual ruin, statistics take note of the same. Statistics leaves a man only after his death — after it has ascertained the precise age of his death and noted the causes that brought about his end.
Ernst Engel, 1862
“You are unfit to ensure the safety of students at UC Davis”
An open letter to Linda Katehi.
She was pretty good at ensuring the admission of children of the wealthy while at UIUC though.
The basketball strike and some confusing lingo
Via Deadspin I saw this AP article on the latest twist in the NBA labor dispute and this tweet from columnist Adrian Wojnarowski : “The chances of losing the entire 2011-12 season has suddenly become the likelihood.” Assuming we correct to “likelihood,” what does this mean from a statistical standpoint? Is this frequentist analysis of a Bayesian procedure? Help me out folks…
HGR maximal correlation and the ratio of mutual informations
From one of the presentation of Zhao and Chia at Allerton this year, I was made aware of a paper by Elza Erkip and Tom Cover on “The efficiency of investment information” that uses one of my favorite quantities, the Hirschfeld–Gebelein–Rényi maximal correlation; I first discovered it in this gem of a paper by Witsenhausen.
The Hirschfeld–Gebelein–Rényi maximal correlation 


![\sup_{f \in \mathcal{F}_X, g \in \mathcal{G}_Y} \mathbb{E}[ f(X) g(Y) ]](https://s0.wp.com/latex.php?latex=%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D_X%2C+g+%5Cin+%5Cmathcal%7BG%7D_Y%7D+%5Cmathbb%7BE%7D%5B+f%28X%29+g%28Y%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
where 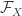
![\mathbb{E}[ f(X) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[ f(X)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)
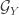
![\mathbb{E}[ g(Y) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[ g(Y)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)


The fact in the Erkip-Cover paper is this one:

That is, the square of the HGR maximal correlation is the best (or worst, depending on your perspective) ratio of the two sides in the Data Processing Inequality:

It’s a bit surprising to me that this fact is not as well known. Perhaps it’s because the “data processing” is happening at the front end here (by choosing 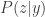

Readings
Tiassa, by Steven Brust. As Cosma puts it, mind candy, and only worth reading if you’ve read the other 10 books in the series. Quite enjoyable, however.
Kraken, by China Miéville. A rollicking adventure involving a giant squid, horrific monsters and gruesome deaths, a dark underbelly of London, the end of the world, and… a ghost piggie. Among other things. I enjoyed it.
Hindoo Holiday, by J.R. Ackerley. A travelogue of a gay Englishman who becomes an attaché to a gay Raja in a princely state in the early 20th century. Often full of colonial condescension (though in a light tone) about things Indian. Most of us are tragically sad of buffoonish. The homosexuality is not overt but explicit enough that the book was censored when published. Still, it’s an interesting historical read, just because it is so weird.
The Lost Promise of Civil Rights, by Risa Goluboff. A really fascinating book about the history of civil rights litigation in the US from Lochner to Brown. The term “civil rights” was in a state of flux during that era, transitioning from a labor-based understanding to discrimination-based standing. The main players were the Justice Department’s Civil Rights Service and the NAACP. By choosing which cases to pursue and which arguments to advance, they explored different visions of what civil rights could mean and why they were rights in the first place. In particular, the NAACP did not take on many labor cases because they were actively pursuing a litigation agenda that culminated in Brown. The decision in Brown and subsequent decisions shaped our modern understanding of civil rights as grounded in stopping state-sanctioned discrimination. However, the “lost promise” in the title shows what was lost in this strategy — the state-sponsored parts of Jim Crow were taken down, but the social institutions that entrench inequality were left.
The Devil in the White City, by Erik Larson. I had to read this since I just moved to Chicago and I work right near Jackson Park. This was a very engaging read (Larson just has that “style”) but a bit creepy in that “watched too many episodes of Dexter” way. I enjoyed it a little less than Thunderstruck, but I had more professional attachment to that one.
