I submitted a paper to ISIT in which I tried something different. It’s about communication models with a jammer, so there are three parties: Alice, Bob, and the jammer. Alice wants to send a message to Bob. The jammer wants to prevent it from being reliably received.
We always use Alice for the encoder/transmitter. Knowing nothing more than the name, I would use the pronouns she/her/hers to refer to Alice.
We always use Bob for the encoder/transmitter. Knowing nothing more than the name, I would use the pronouns he/him/his to refer to Bob.
What about the jammer? In previous papers (and in our research discussions) we called the jammer various names: Calvin (to get the C) or James (for the J). We ended up also using he/him/his for the jammer too.
This time I proposed we use Jamie for the jammer. Knowing nothing more than the name, I suggested they/them/their as the most appropriate. In my mind, Jamie may be gender nonconforming, right?
At this point many readers (if there are any) would say I’m being a bit on the nose. Why make James into Jamie and why deliberately change the pronouns? Won’t it just confuse people?
There are so many responses to this.
First, just on pragmatics. This makes pronouns which are uniquely decodable to the parties in the communication model. What can be clearer?
Second, if pronouns create a problem for a mathematically-minded reader, then they are far too obsessed with (gendered) Alice/Bob metaphor. It’s a mathematical engineering paper, not a kid’s story.
But finally, and most importantly, even though all the authors of this paper may be cis-gendered, writing the stories in our papers in a more inclusive way is the right thing to do. Why Alice and Bob? Why not Aarti and Bhaskar, Anting and Bolei, Avital and Binyamin, or Arash and Babak? I’ve heard arguments that we should be more ecumenical in the national origin of our communicating parties. Can we be more inclusive by gender as well?
We can and should!
 -sided die with numbers
-sided die with numbers 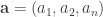 and call
and call  the face sum. The die is fair, so the expected face value is
the face sum. The die is fair, so the expected face value is  . We can define an ordering on dice by saying $\mathbf{a} \succ \mathbf{b}$ if a uniformly chosen face of
. We can define an ordering on dice by saying $\mathbf{a} \succ \mathbf{b}$ if a uniformly chosen face of 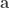 is larger than a uniformly chosen face of
is larger than a uniformly chosen face of 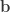 . That is, if you roll both dice then on average
. That is, if you roll both dice then on average 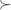 based on dice beating each other cannot be extended to a linear order. The connection to elections is in ranked voting — an election in which voters rank candidates may exhibit a
based on dice beating each other cannot be extended to a linear order. The connection to elections is in ranked voting — an election in which voters rank candidates may exhibit a ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and condition on the face sum being equal to
and condition on the face sum being equal to  . Then as the number of faces
. Then as the number of faces 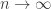 , three such independently generated dice will become intransitive with high probability (see the
, three such independently generated dice will become intransitive with high probability (see the 