For our first-year seminar, we wanted to get the students to read some the hyperbolic articles on data science. A classic example is the Harvard Business Review’s Data Scientist: The Sexiest Job of the 21st Century. However, when we downloaded the PDF version through the library proxy, we were informed:
Harvard Business Review and Harvard Business Publishing Newsletter content on EBSCOhost is licensed for the private individual use of authorized EBSCOhost users. It is not intended for use as assigned course material in academic institutions nor as corporate learning or training materials in businesses. Academic licensees may not use this content in electronic reserves, electronic course packs, persistent linking from syllabi or by any other means of incorporating the content into course resources
Harvard Business Publishing will be pleased to grant permission to make this content available through such means. For rates and permission, contact permissions@harvardbusiness.org.
So it seems that for a single article we’d have to pay extra, and since “any other means of incorporating the content” is also a violation, we couldn’t tell the students that they can go to the library website and look up an article in a publication whose name sounds like “Schmarbard Fizzness Enqueue” on sexy data science.
My first thought on seeing this restriction is that it would definitely not pass the fair use test, but then the fine folks at the American Library Association say that it’s a little murky:
Is There a Fair Use Issue? Despite any stated restrictions, fair use should apply to the print journal subscriptions. With the database however, libraries have signed a license that stipulates conditions of use, so legally are bound by the license terms. What hasn’t really been fully tested is whether federal law (i.e. copyright law) preempts a license like this. While librarians may like to think it does, there is very little case law. Also, it is possible that if Harvard could prove that course packs and article permission fees are a major revenue source for them, it would be harder to declare fair use as an issue and fail the market effect factor. In other cases as in Georgia State, the publishers could not prove their permissions business was that significant which worked against them. Remember that if Harvard could prove that schools were abusing the restrictions on use, they could sue.
Part of the ALA’s advice is to use “alternate articles to the HBR 500 supplied by other vendors that do not have these restrictions.” Luckily for us, there is no absence of hype on data science, so we could avoid it.
Given Harvard’s well-publicized open access policy and general commitment to sharing scholarly materials, the educational restriction on using materials strikes me as rank hypocrisy. Of course, maybe HBR is not really a venue for scholarly articles. Regardless, I would urge anyone considering including HBR material in their class to think twice before playing their game. Or to indulge in some civil disobedience, but this might end up hurting the libraries and not HBR, so it’s hard to figure out what to do.
 where each codeword is a superposition of
where each codeword is a superposition of  columns, one each from groups of size
columns, one each from groups of size  . Thus encoding is
. Thus encoding is  where
where  is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as
is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as 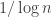 . Ramji gave a really nice and clear talk on this — I hope he puts the slides up!
. Ramji gave a really nice and clear talk on this — I hope he puts the slides up!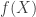 on
on  , we can define
, we can define  . The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions
. The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions 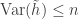 . This bound doesn’t depend on the distribution and is sharp if
. This bound doesn’t depend on the distribution and is sharp if  is a product of exponentials. They then use this to prove a universal bound on the deviation of
is a product of exponentials. They then use this to prove a universal bound on the deviation of  from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper.
from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper. ‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible
‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible  a deletion more.
a deletion more.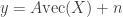 where
where  is a low-rank matrix and
is a low-rank matrix and  is noise. The previous state of the art is by
is noise. The previous state of the art is by ![\min_{X_i} \sum_{i} \alpha_i \mathrm{rank}[X_i] \ \ \ \ \ \ \ Y = \sum_{i} A_i(X_i)](https://s0.wp.com/latex.php?latex=%5Cmin_%7BX_i%7D+%5Csum_%7Bi%7D+%5Calpha_i+%5Cmathrm%7Brank%7D%5BX_i%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+Y+%3D+%5Csum_%7Bi%7D+A_i%28X_i%29&bg=ffffff&fg=333333&s=0&c=20201002)
 are some operators. He made the case that convex relaxations of many of these problems, while analytically beautiful, have restrictions which are not satisfied in practice, and indeed they often have poor performance. His approach is via Empirical Bayes, but this leads to non-convex problems. What he can show is that the algorithm he proposes is competitive with any method that tries to separate the error from the “low-rank” constraint, and that the new optimization is “smoother.” I’m sure more details are in his various papers, for those who are interested.
are some operators. He made the case that convex relaxations of many of these problems, while analytically beautiful, have restrictions which are not satisfied in practice, and indeed they often have poor performance. His approach is via Empirical Bayes, but this leads to non-convex problems. What he can show is that the algorithm he proposes is competitive with any method that tries to separate the error from the “low-rank” constraint, and that the new optimization is “smoother.” I’m sure more details are in his various papers, for those who are interested.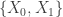 , Yvonne has
, Yvonne has 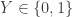 and Zelda wants
and Zelda wants 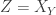 , but nobody should be able to infer each other’s values.
, but nobody should be able to infer each other’s values. 