I did catch Greg Wornell’s plenary at SPCOM, which was called When Bits Absolutely, Positively, Have to be There as Soon as Possible, a riff on this FedEx commercial, which is older than I am. The talk was on link-aware PHY-layer design– basically looking at how ARQ enables incremental redundancy, and how to do a sort of layered superposition + incremental redundancy scheme in the sequential setting as well as a “multi-path” setting where blocks can arrive out of order. This was really digging into the signal issues in a way that a lot of non-communication engineering information theorists may get squeamish about. The nice thing is that I think the engineering problem is approachable without knowing a lot of heavy-duty math, but still requires some careful analysis.
Communication and Compression Via Sparse Linear Regression
Ramji Venkataramanan
This was on building codewords and codebooks out of a lower-complexity code dictionary 




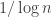
An Optimal Varentropy Bound for Log-Concave Distributions
Mokshay Madiman; Liyao Wang
Mokshay’s talk was also really clear and excellent. For a distribution 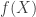


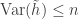


Event-triggered Sampling and Reconstruction of Sparse Real-valued Trigonometric Polynomials
Neeraj Sharma; Thippur V. Sreenivas
This was on non-uniform sampling where the sampler tries to detect level crossings of the analog signal and samples at that point — the rate may not be uniform enough to use existing nonuniform sampling techniques. They come up with a method for reconstructing signals which are real-valued trigonometric polynomials with a few nonzero coefficients (e.g. sparse) and it seems to work pretty decently in experiments.
Removing Sampling Bias in Networked Stochastic Approximation
Vivek Borkar; Raaz Dwivedi
In networked stochastic approximation, the intermittent communication between nodes may mean that the system tracks a different ODE than the one we want. By modifying the method to account for “local clocks” on each edge, we can correct for this, but we end up with new conditions on the step size to make things work. I am pretty excited about this paper, but as usual, my notes were not quite up to getting the juicy bits. That’s what paper reading is for.
On Asymmetric Insertion and Deletion Errors
Ankur A. Kulkarni
The insertion/deletion channel model is notoriously hard. Ankur proposed a new model where 


Hi Anand, The slides from my talk are here: http://goo.gl/4XvqqX