Last week I saw this in the library at UCSD:

One of these things does not belong in QA279
What is that, you might ask? Why it’s
The Design Inference, by noted Intelligent Design proponent William Dembski. I thought perhaps some enterprising soul had hidden it away in QA279, the Library of Congress call number for experimental design, to keep it away from the corruptible undergraduate youth. However, much to my surprise, it was correctly shelved. I suppose you
could call it a book on experiments, but it’s a far cry from D.A. Freedman’s
Statistical models : theory and practice. I wonder what the LC call number is for pseudomathematical quackery?
 whose entries
whose entries 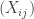 are drawn iid complex circularly-symmetric Gaussian
are drawn iid complex circularly-symmetric Gaussian  . In the course of computing the expected value of the 4th moment of the permanent, he gave the following cute result as a puzzle. Given a permutation
. In the course of computing the expected value of the 4th moment of the permanent, he gave the following cute result as a puzzle. Given a permutation  of length
of length  , let
, let  be the number of cycles in
be the number of cycles in ![\mathbb{E}[ 2^{c(\sigma)}] = n + 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+2%5E%7Bc%28%5Csigma%29%7D%5D+%3D+n+%2B+1&bg=ffffff&fg=333333&s=0&c=20201002) .
. and then look at the variables in question.
and then look at the variables in question.


