A while ago, Alex Dimakis sent me an EFF article on information theory and privacy, which starts out with an observation of Latanya Sweeney’s that gender, ZIP code, birthdate are uniquely identifying for a large portion of the population (an updated observation was made in 2006).
What’s weird is that the article veers into “how many bits of do you need to uniquely identify someone” based on self-information or surprisal calculations. It paints a bit of a misleading picture about how to answer the question. I’d probably start with taking 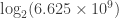
However, the mere existence of this article raises a point : here is a situation where ideas from information theory and probability/statistics can be made relevant to a larger population. It’s a great opportunity to popularize our field (and demonstrate good ways of thinking about it). Why not do it ourselves?

And we are going to :). Don’t tell others to do it; lets just do it.
That said, I too have been pained by the CS/data-mining community’s misuse of mutual information to obtain a measure of worst case privacy estimate. The formulation from an IT-perspective is meaningless but then its a highly cited paper in the mining community!
I am confused about what you find weird about the article. They *do* start with that log and then look at the variables in question, right?
It’s not quite correct (as the article points out only later) to calculate the entropy of different variables and then say “oh well, add up the entropies and you get enough bits.” This is because the variables are correlated.
Furthermore, using the self-information doesn’t necessarily make sense in this context. What you might want to quantify is, say, the conditional entropy of a random person conditioned on the three observed variables.
conditioned on the three observed variables.
The ad-hoc-ness of the presented calculations is what I find weird, in the end.
Th article does say that there is this specific caveat though; see footnote (5).
Hmmm, maybe my discomfort is not being properly expressed — I don’t have a problem with the discussion for a technical audience (which might read/understand the caveats), but rather for a general audience. Most people will not read the footnotes with the caveats, and I think the caveats are important. This is speaking with my professional hat on of course…
The reality of many fields is that people from a given field rarely find it exciting or purposeful to do some basic calculations using their techniques. But in some other field, those things look deep and interesting so there is some motivation…
I found the article somewhat reasonable, although I would have presented it using conditional probabilities. But then again, for the layman conditional probability = oblivion…
On another note, I really think our field (systems science) should train us both on working on theory/algorithms and on modeling real problems and finding out things from data…