Sofya Raskhodnikova and Adam Smith are looking to fill a postdoc position at Penn State for a multi-year project on privacy, streaming and learning.
Qualifications: Ph.D., with expertise in the theoretical foundations of at least one of the research areas (algorithms, machine learning and statistics, data privacy). Willingness to work on a cross-disciplinary project.
More about the project leaders: Sofya Raskhodnikova, Adam Smith.
Duration and compensation: At least one year, renewable. Start date is
negotiable, though we slightly prefer candidates starting fall 2015. Salary is competitive.
Applicants should email a CV, short research statement and list of references directly to the project leaders ({asmith,sofya}@cse.psu.edu) with “postdoc” in the subject line.
Location: The university is located in the beautiful college town of
State College in the center of Pennsylvania. The State College area has 130,000 inhabitants and offers a wide variety of cultural and outdoor recreational activities. The university offers outstanding events from collegiate sporting events to fine arts productions. Many major population centers on the east coast (New York, Philadelphia, Pittsburgh, Washington D.C., Baltimore) are only a few hours’ drive away and convenient air services to several major hubs are operated by three major airlines out of State College.
Penn State is an equal opportunity employer. We encourage applications from underrepresented minorities.
 coins with biases
coins with biases ![\{p_i : i \in [n]\}](https://s0.wp.com/latex.php?latex=%5C%7Bp_i+%3A+i+%5Cin+%5Bn%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . For some given
. For some given ![p \in [\epsilon,1-\epsilon]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B%5Cepsilon%2C1-%5Cepsilon%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 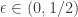 , each coin is “heavy” (
, each coin is “heavy” (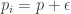 ) with probability
) with probability  and “light” (
and “light” (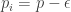 ) with probability
) with probability 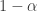 . The goal is to use a sequential flipping strategy to find a heavy coin with probability at least
. The goal is to use a sequential flipping strategy to find a heavy coin with probability at least  .
. . On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.
. On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.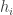 heads and
heads and  tails, then the likelihood ratio is
tails, then the likelihood ratio is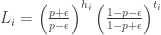
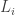 so far (breaking ties arbitrarily).
so far (breaking ties arbitrarily). . These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
. These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which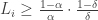
 heads and tails for a coin $i$,
heads and tails for a coin $i$,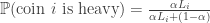 ,
,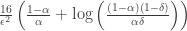
 data matrix
data matrix  into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here
into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here  the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that
the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that 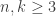 . “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.”
. “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.” where
where 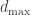 is the maximum degree in the graph. They also showed the barbell graph is very very slow.
is the maximum degree in the graph. They also showed the barbell graph is very very slow.