After a long stint of proposal writing, I figured I should catch up on some old languishing posts. So here’s a few quick notes on the remainder of ICML 2014.
- Fast Stochastic Alternating Direction Method of Multipliers (Wenliang Zhong; James Kwok): Most of the talks in the Optimization II session were on ADMM or stochastic optimization, or both. This was int he last category. ADMM can have rather high-complexity update rules, especially on large, complex problems, so the goal is to lower the complexity of the update step by making it stochastic. The hard part seems to be controlling the step size.
- An Asynchronous Parallel Stochastic Coordinate Descent Algorithm (Ji Liu; Steve Wright; Christopher Re; Victor Bittorf; Srikrishna Sridhar): The full version of this paper is on ArXiV. The authors look at a multi-core lock-free stochastic coordinate descent method and characterize how many cores you need to get linear speedups — this depends on the convexity properties of the objective function.
- Communication-Efficient Distributed Optimization using an Approximate Newton-type Method (Ohad Shamir; Nati Srebro; Tong Zhang): This paper looked 1-shot “average at the end” schemes where you divide the data onto multiple machines, have them each train a linear predictor (for example) using stochastic optimization and then average the results. This is just averaging i.i.d. copies of some complicated random variable (the output of an optimization) so you would expect some variance reduction. This method has been studied by a few people int the last few years. While you do get variance reduction, the bias can still be bad. On the other extreme, communicating at every iteration essentially transmits the entire data set (or worse) over the network. They propose a new method for limiting communication by computing an approximate Newton step without approximating the full Hessian. It works pretty well.
- Lower Bounds for the Gibbs Sampler over Mixtures of Gaussians (Christopher Tosh; Sanjoy Dasgupta): This was a great talk about how MCMC can be really slow to converge. The model is a mixture of Gaussians with random weights (Dirichlet) and means (Gaussian I think). Since the posterior on the parameters is hard to compute, you might want to do Gibbs sampling. They use conductance methods to get a lower bound on the mixing time of the chain. The tricky part is that the cluster labels are permutation invariant — I don’t care if you label clusters (1,2) versus (2,1), so they need to construct some equivalence classes. They also have further results on what happens when the number of clusters is misspecified. I really liked this talk because MCMC always seems like black magic to me (and I even used it in a paper!)
- (Near) Dimension Independent Risk Bounds for Differentially Private Learning (Prateek Jain; Abhradeep Guha Thakurta): Abhradeep presented a really nice paper with a tighter analysis of output and objective perturbation methods for differentially private ERM, along with a new algorithm for risk minimization on the simplex. Abhradeep really only talked about the first part. If you focus on scalar regret, they show that essentially the error comes from taking the inner product of a noise vector with a data vector. If the noise is Gaussian then the noise level is dimension-independent for bounded data. This shows that taking
-differential privacy yield better sample complexity results than
-differential privacy. This feels similar in flavor to a recent preprint on ArXiV by Beimel, Nissim, and Stemmer.
- Near-Optimally Teaching the Crowd to Classify (Adish Singla; Ilija Bogunovic; Gabor Bartok; Amin Karbasi; Andreas Krause): This was one of those talks where I would have to go back to look at the paper a bit more. The idea is that you want to train annotators to do better in a crowd system like Mechanical Turk — which examples should you give them to improve their performance? They model the learners as doing some multiplicative weights update. Under that model, the teacher has to optimize to pick a batch of examples to give to the learner. This is hard, so they use a submodular surrogate function and optimize over that.
- Discrete Chebyshev Classifiers (Elad Eban; Elad Mezuman; Amir Globerson): This was an award-winner. The setup is that you have categorical (not numerical) features on
variables and you want to do some classification. They consider taking pairwise inputs and compute for each tuple
a marginal
. If you want to create a rule
for classification, you might want to pick one that has best worst-case performance. One approach is to take the one which has best worst-case performance over all joint distributions on all variables that agree with the empirical marginals. This optimization looks hard because of the exponential number of variables, but they in fact show via convex duality and LP relaxations that it can be solved efficiently. To which I say: wow! More details are in the paper, but the proofs seem to be waiting for a journal version.
 where
where  is low-rank and
is low-rank and  is sparse, recover
is sparse, recover 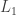 regularization, which they claim implies a kind of Laplace-like model for the noise. They build a generative model and then change the distributions around to get different noise models.
regularization, which they claim implies a kind of Laplace-like model for the noise. They build a generative model and then change the distributions around to get different noise models.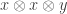 where
where  are the features and
are the features and  are the labels, and to then find generalized eigenvalues and eigenvectors by looking for vectors
are the labels, and to then find generalized eigenvalues and eigenvectors by looking for vectors  that maximize (for a given
that maximize (for a given  the ratio
the ratio ![\frac{ \mathbb{E}[ (v^{\top} x)^2 | y = i] }{ \mathbb{E}[ (v^{\top} x)^2 | y = j] }](https://s0.wp.com/latex.php?latex=%5Cfrac%7B+%5Cmathbb%7BE%7D%5B+%28v%5E%7B%5Ctop%7D+x%29%5E2+%7C+y+%3D+i%5D+%7D%7B+%5Cmathbb%7BE%7D%5B+%28v%5E%7B%5Ctop%7D+x%29%5E2+%7C+y+%3D+j%5D+%7D&bg=ffffff&fg=333333&s=0&c=20201002) . This nonlinearity is important for reasons which I wasn’t entirely sure about.
. This nonlinearity is important for reasons which I wasn’t entirely sure about.

