I recently re-read my old roommate Samidh Chakrabarti’s master’s thesis : Transacting Philosophy : A History of Peer Review in Scientific Journals (Oxford, 2004). It’s a fascinating history of scientific publishing from the Royal Society up to the present, and shows that “peer review has never been inseparable from the scientific method.” His analysis is summed up in the following cartoon, which shows three distinct phases of peer review:

When there are few journals but a large supply of papers, peer review is necessary to select the papers to be published. However, when printing became cheap in the 19th century, everybody and their uncle had a journal and sometimes had to solicit papers to fill their pages. After WWII the trend reversed again, so now peer review is “in.” In this longish post I’m going to summarize/highlight a few things I learned.
The first scientific journal was started by the Royal Society, called Philosophical Transactions: giving some Account of the Present Undertakings, Studies and Labours of the Ingenious in many considerable Parts of the World, but is usually shortened to Phil. Trans.. Henry Oldenburg, the secretary of the Society, came up with the idea of using referees. Samidh’s claim is that Oldenburg was motivated by intellectual property claims. Time stamps for submitted documents would let philosophers establish when they made a discovery — Olderburg essentially made Phil. Trans. the arbiter of priority. However, peer review was necessary to provide quality guarantees, since the Royal Society was putting their name on it. He furthermore singled out articles which were not reviewed by putting the following disclaimer:
sit penes authorem fides [let the author take responsibility for it]: We only set it downe, as it was related to us, without putting any great weight upon it.”
Phil. Trans. was quite popular but not profitable. The Society ended up taking over the full responsibility (including fiscal) of the journal, and decided that peer review would not be about endorsing the papers or guaranteeing correctness:
And the grounds of their choice are, and will continue to be, the importance or singularity of the subjects, or the advantageous manner of treating them; without pretending to answer for the certainty of the facts, or propriety of the reasonings, contained in the several papers so published, which must still rest on the credit or judgment of their respective authors.
In the 19th century all this changed. Peer review began to smack of anti-democracy (compare this to the intelligent design crowd now), and doctors of medicine were upset ever since Edward Jenner’s development of the vaccine for smallpox in 1796 was rejected by the Royal Society for having too small a sample size. Peer review made it tough for younger scientists to be heard, and politics played no small role in papers getting rejected. Those journals which still practiced peer review sometimes paid a hefty price. Samidh writes of Einstein:
In 1937 (a time when he was already a celebrity), he submitted an article to Physical Review, one of the most prestigious physics journals. The referees sent Einstein a letter requesting a few revisions before they would publish his article. Einstein was so enraged by the reviews that he fired off a letter to the editor of Physical Review in which he strongly criticized the editor for having shown his paper to other researchers… he retaliated by never publishing in Physical Review again, save a note of protest.
The 19th century also saw the rise of cheap printing and the industrial revolution which created a larger middle class that was literate and interested in science. A lot hadn’t been discovered yet, and an amateur scientist could still make interesting discoveries with their home microscope. There was a dramatic increase in magazines, journals, gazettes, and other publications, each with their own editor, and each with a burning need to fill their pages.
The content of these new scientific journals became a reflection of the moods and ideas of their editors. Even the modern behemoths, Science and Nature, used virtually no peer review. James McKeen Cattell, the editor of Science from 1895-1944 got most of his content from personal solicitations. The editor of Nature would just ask people around the office or his friends at the club. Indeed, the Watson-Crick paper on the structure of DNA was not reviewed because the editor said “its correctness is self-evident.”
As the 20th century dawned, science became more specialized and discoveries became more rapid, so that editors could not themselves curate the contents of their journals. As the curve shows, the number of papers written started to exceed the demand of the journals. In order to maintain their competitive edge and get the “best” papers, peer review became necessary again.
Another important factor was the rise of Nazi Germany and the corresponding decline of German science as Jewish and other scientists fled. Elsevier hired these exiles to start a number of new journals with translations into English, and became a serious player in the scientific publishing business. And it was a business — Elsevier could publish more “risky” research because it had other revenue streams, and so it could publish a large volume of research than other publishers. This was good and bad for science as a whole — journals were published more regularly, but the content was mixed. After the war, investment in science and technology research increased; since the commercial publishers were more established, they had an edge.
How could the quality of a journal be measured?
Eugene Garfield came up with a method of providing exactly this kind of information starting in 1955, though it wasn’t his original intent. Garfield was intrigued by the problem of how to trace the lineage of scientific ideas. He wanted to know how the ideas presented in an article percolated down through other papers and led to the development of new ideas. Garfield drew his inspiration from law indexes. These volumes listed a host of court decisions. Under each decision, they listed all subsequent decisions that used it as a precedent. Garfield realized that he could do the same thing with scientific papers using bibliographical citations. He conceived of creating an index that not only listed published scientific articles, but also listed all subsequent articles that cited each article in question. Garfield founded the Institute for Scientific Information (ISI) to make his vision a reality. By 1963, ISI had published the first incarnation of Garfield’s index, which it called the Science Citation Index.
And hence the impact factor was born — a ratio of citations to citable articles. This proved to be helpful to librarians as well as tenure and promotion committees. They just had to look at the aggregate impact of a professor’s research. Everything became about the impact factor, and the way to improve the impact factor of a journal was to improve the quality (or at least perceived quality) of its peer review. And fortunately, most of it was (and is) given for free — “unpaid editorial review is the only thing keeping the journal industry solvent.” However, as Samidh puts it succinctly in his thesis:
All of this sets aside the issue of whether the referee system in fact provides the best possible quality control. But this merely underscores the fact that in the historical record, the question of peer review’s efficacy has always been largely disconnected from its institutionalization. To summarize the record, peer review became institutionalized largely because it helped commercial publishers inexpensively sustain high impact factors and maintain exalted positions in the hierarchy of journals. Without this hierarchy, profits would vanish. And without this hierarchy, the entire system of academic promotion in universities would be called into question. Hence, every scientist’s livelihood depends on peer review and it has become fundamental to the professional organization of science. As science is an institution chiefly concerned with illuminating the truth, it’s small wonder, then, that editorial peer review has become confused with truth validation.
It seems all like a vicious cycle — is there any way out? Samidh claims that we’re moving to a “publish, then filter” approach where things are put on ArXiV and then are reviewed. He’s optimistic about “a system where truth is debated, not assumed, and where publication is for the love of knowledge, not prestige.” I’m a little more dubious, to be honest. But it’s a fascinating history, and some historical perspective may yield clues about how to design a system with the right incentives for the future of scientific publishing.
 , where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of
, where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of 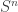 sequences. That is, given a code and a set of almost
sequences. That is, given a code and a set of almost 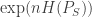 typical sequences in
typical sequences in 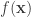 from long binary strings
from long binary strings 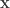 so that a verifier can look at a new long vector
so that a verifier can look at a new long vector 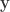 and tell whether or not
and tell whether or not 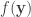 . They develop a scheme which stores the index of a reference vector
. They develop a scheme which stores the index of a reference vector  that is “close” to
that is “close” to  . This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate.
. This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate. pirates can identify at least one of the pirates. In the two-level problem, the objects are coarsely classified into groups (e.g. by geographic region) and the verifier wants to be able to identify one of the groups of one of the pirates when there are more than
pirates can identify at least one of the pirates. In the two-level problem, the objects are coarsely classified into groups (e.g. by geographic region) and the verifier wants to be able to identify one of the groups of one of the pirates when there are more than 