Sudeep Kamath sent me a note about a recent result he posted on the ArXiV that relates to an earlier post of mine on the HGR maximal correlation and an inequality by Erkip and Cover for Markov chains 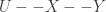
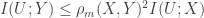
Since learning about this inequality, I’ve seen a few talks which have used the inequality in their proofs, at Allerton in 2011 and at ITA this year. Unfortunately, the stated inequality is not correct!
On Maximal Correlation, Hypercontractivity, and the Data Processing Inequality studied by Erkip and Cover
Venkat Anantharam, Amin Gohari, Sudeep Kamath, Chandra Nair
What this paper shows is that the inequality is not satisfied with 
where 

Let
and
be random variables with joint distribution
. We define
,
wheredenotes the
-marginal distribution of
and the supremum on the right hand side is over all probability distributions
that are different from the probability distribution
. If either
to be 0.
Suppose 

Rather than getting into that in the blog post, I recommend reading the paper.

The implication of this result is that the inequality of Erkip and Cover is not correct : not only is 

Joint distribution counterexample (Fig. 2 of the paper)
How can we calculate
 ? If either or is binary-valued, then
? If either or is binary-valued, then
So for this example
 . However,
. However, 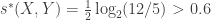 and there exists a sequence of variables
and there exists a sequence of variables  satisfying the Markov chain such that
satisfying the Markov chain such that  such that the ratio approaches .
such that the ratio approaches .
So where is the error in the original proof? Anantharam et al. point to an explanation that the Taylor series expansion used in the proof of the inequality with
This seems to just be the start of a longer story, which I look forward to reading in the future!
 -dimensional data points
-dimensional data points ![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) the Lasso tries to fit the model
the Lasso tries to fit the model 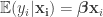 by minimizing the
by minimizing the 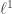 penalized squared error
penalized squared error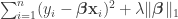 .
. i.i.d. copies of a pair of random variables
i.i.d. copies of a pair of random variables  so the data is
so the data is ![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The assumptions are on the random variables
. The assumptions are on the random variables 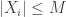 is bounded, the variable
is bounded, the variable  , and
, and  , where
, where  and
and  are unknown constants. Basically that’s all that’s needed — given a bound on
are unknown constants. Basically that’s all that’s needed — given a bound on  , he derives a bound on the mean-squared prediction error.
, he derives a bound on the mean-squared prediction error.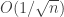 , can be improved to
, can be improved to  . Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic.
. Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic. be
be 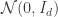 in
in 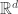 . The convex hull
. The convex hull  of these points is called a Gaussian polytope. This is a random polytope of course, and we can ask various things about their shape : what is the distribution of the number of vertices, or the number of
of these points is called a Gaussian polytope. This is a random polytope of course, and we can ask various things about their shape : what is the distribution of the number of vertices, or the number of  -faces? Let
-faces? Let  be the number of
be the number of  ) is given by
) is given by![\mathbb{E}[ f_k(P_n)] = \frac{2^d}{\sqrt{d}} \binom{d}{k+1} \beta_{k,d-1}(\pi \ln n)^{(d-1)/2} (1 + o(1))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f_k%28P_n%29%5D+%3D+%5Cfrac%7B2%5Ed%7D%7B%5Csqrt%7Bd%7D%7D+%5Cbinom%7Bd%7D%7Bk%2B1%7D+%5Cbeta_%7Bk%2Cd-1%7D%28%5Cpi+%5Cln+n%29%5E%7B%28d-1%29%2F2%7D+%281+%2B+o%281%29%29&bg=ffffff&fg=333333&s=0&c=20201002) ,
,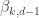 is the internal angle of a regular
is the internal angle of a regular  -simplex at one of its
-simplex at one of its  such that
such that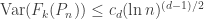
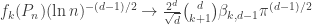
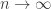 . That is, appropriately normalized, the number of faces converges to a constant.
. That is, appropriately normalized, the number of faces converges to a constant.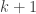 points to define a
points to define a  fraction of them will form a real
fraction of them will form a real  , regardless of
, regardless of  -divergences, which are given by
-divergences, which are given by
 — you have to take the limit as
— you have to take the limit as 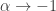 . Within this family of divergences we have the relation
. Within this family of divergences we have the relation  . Consider a pair of random variables
. Consider a pair of random variables 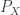 and
and 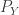 . If we take
. If we take  and
and  then the mutual information is
then the mutual information is  . But we can also take
. But we can also take

{kind=link}