I recently posted a link to an article on mental health in graduate school on Facebook (via a grad school friend of mine), and it sparked a fair bit of discussion there. The article is worth reading, and I am sure will echo with many of the readers. The discussion veered towards particularities of graduate school pressures in STEM, and the contributing factors to mental stress that are driven by funding structures and the advisor/student relationship. The starting point comes from this part of the article:
In this advisor-advisee arrangement, the student trades her labor as a researcher for the advisor’s mentorship and, ultimately, the advisor’s approval of her degree before she can graduate. For students seeking an academic position after graduate school, an advisor’s letter of recommendation can be the difference between landing a job and being left out in the cold, a harsh reality given today’s sparse academic job market. All of these factors mean that the faculty advisors hold tremendous power in the advisor-advisee relationships. They are the gatekeepers of success in the graduate endeavor.
This notion of “trading labor for mentorship” is most directly monetized in grant-funded fields like engineering, where graduate students are “working in the lab” on a project that is (hopefully) related to their thesis topic. In some cases, this works out fine, but in others, the research for the grant-relevant project does not contribute directly to their thesis. For funding agencies which want “deliverables,” this pressure to produce results on schedule creates a tension. The advisor becomes a boss.
Some of the points raised in the discussion on Facebook seemed important to bring out to a wider audience. One suggestion is to disentangle NSF support for projects and research from grad student salaries. So students could apply for NSF support and then they take their funding with them to find an advisor. In STEM this would be difficult, given the large number of international students who would not be qualified for such support, but it does give some power to students to walk away from a bad situation and more incentives for PIs to be more mentors than bosses. I am not entirely convinced it would help in terms of mental health though — students need more and better mentoring, not just the means to walk away. Also, Roy pointed out, having the student and advisor both convinced that a problem is important and solvable creates a shared commitment that helps students feel less isolated. For postdocs, though, this model would be a significant improvement over the status quo. Right now, there is almost no consensus on what a postdoc should be, and I’ve seen postdoc jobs that range from factotum to co-PI.
When one is on the other side (post-PhD), it’s tempting to say that grad school would have been easier if I had been a bit more organized or had better time-management skills. Perhaps the difficulties one has can be solved with “one weird trick.” I think that’s terribly naïve. As advisors, we definitely can do things to help students learn to work better — that’s the transition from being a student to being a researcher. But the notion that depression comes about as a result of simply not being productive enough, or feeling behind, or any other “outcomes”-based reason, misses the environmental and social factors that are equally important.
Graduate research is often very isolating. Perhaps some STEM students actually enjoy this kind of solitary work, but generalizing is dangerous. Having a grad student social organization, weekly happy hour, softball league, or other “outlet” isn’t enough. I used my startup funds to help buy a table-tennis table for my department at Rutgers, and while the students seem pretty happy about it, it’s not actually creating a community. One important question to ask is how the faculty and the department can help create and support that kind of community so that it can go on its own, organically.
In a department like mine, the majority of graduate students are international, and have a host of other stressors about being in a new (and often much more expensive) country. Using mental health resources may not be normalized in their home country or culture. Regardless of where they are from however, the big challenge is this:
…awareness of the existing resources among the graduate student population remains frustratingly low, due in part to the insular nature of traditional academic departments. A broader culture of wellness may prove even more elusive in the face of a rigidly hierarchical academic culture that often rewards drive and sacrifice without encouraging balance. In this climate, graduate student mental health advocates—students, staff, and administrators—face an uphill struggle in the years to come. The consequences of this struggle tear at the very fabric of the academic experience and suggest fundamental misalignment of priorities.
It’s only a misalignment of priorities if we don’t interrogate our priorities. This isn’t two trains crashing into each other, but it does require a “structural” recognition that graduate students are a part of the family, as it were, and treating them as such.
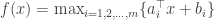
 belonging to some convex polytope
belonging to some convex polytope  . This is a bit different than the kind of convex programs I’ve been looking at (which are more ERM-like). Such programs occur often in resource allocation problems. Here the private information of users are the offsets
. This is a bit different than the kind of convex programs I’ve been looking at (which are more ERM-like). Such programs occur often in resource allocation problems. Here the private information of users are the offsets  . They propose a number of methods for generating differentially private approximations to this problem. Analyzing the sensitivity of this optimization is tricky, so they use an upper bound based on the diameter of the feasible set $\mathcal{P}$ to find an appropriate noise variance. The exponential mechanism also gives a feasible mechanism, although the exact dependence of the suboptimality gap on
. They propose a number of methods for generating differentially private approximations to this problem. Analyzing the sensitivity of this optimization is tricky, so they use an upper bound based on the diameter of the feasible set $\mathcal{P}$ to find an appropriate noise variance. The exponential mechanism also gives a feasible mechanism, although the exact dependence of the suboptimality gap on  is unclear. They also propose a noisy subgradient method where, instead of using SGD, they alter the sampling distribution using the exponential mechanism to choose a gradient step. Some preliminary experiments are also given (although none exploring the dependence on
is unclear. They also propose a noisy subgradient method where, instead of using SGD, they alter the sampling distribution using the exponential mechanism to choose a gradient step. Some preliminary experiments are also given (although none exploring the dependence on 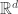 .
.
 and
and  satisfies a power constraint
satisfies a power constraint  . The lazy calculation goes like this. For any particular message
. The lazy calculation goes like this. For any particular message  , the codeword
, the codeword 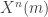 is going to be i.i.d.
is going to be i.i.d.  , so with high probability it has length
, so with high probability it has length  . The noise is independent and
. The noise is independent and ![\mathbb{E}[ X Z ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+X+Z+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002) so
so  with high probability, so
with high probability, so 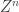 is more-or-less orthogonal to
is more-or-less orthogonal to  with high probability. So we have the following right triangle:
with high probability. So we have the following right triangle:
 using basic trigonometry:
using basic trigonometry: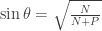 ,
,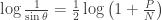 ,
,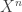 with variance
with variance  , distortion
, distortion  and a quantization vector
and a quantization vector  . But now we have a different right triangle:
. But now we have a different right triangle:
 .
.![\mathbb{E}[ X Z ] = - \rho](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+X+Z+%5D+%3D+-+%5Crho&bg=ffffff&fg=333333&s=0&c=20201002) ? Then the cosine of the angle between
? Then the cosine of the angle between  in the picture is
in the picture is 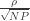 and we have a general triangle like this:
and we have a general triangle like this:
 using the law of cosines:
using the law of cosines: .
. again. The cosine is easy to find:
again. The cosine is easy to find: .
.
 ,
,
 we get back the AWGN capacity and if we plug in
we get back the AWGN capacity and if we plug in  we get the rate distortion function, but this formula gives the capacity for a range of correlated noise channels.
we get the rate distortion function, but this formula gives the capacity for a range of correlated noise channels.