Privacy Preserving Machine Learning
NIPS 2018 Workshop
Montreal, December 8, 2018
Description
This one day workshop focuses on privacy preserving techniques for training, inference, and disclosure in large scale data analysis, both in the distributed and centralized settings. We have observed increasing interest of the ML community in leveraging cryptographic techniques such as Multi-Party Computation (MPC) and Homomorphic Encryption (HE) for privacy preserving training and inference, as well as Differential Privacy (DP) for disclosure. Simultaneously, the systems security and cryptography community has proposed various secure frameworks for ML. We encourage both theory and application-oriented submissions exploring a range of approaches, including:
- secure multi-party computation techniques for ML
- homomorphic encryption techniques for ML
- hardware-based approaches to privacy preserving ML
- centralized and decentralized protocols for learning on encrypted data
- differential privacy: theory, applications, and implementations
- statistical notions of privacy including relaxations of differential privacy
- empirical and theoretical comparisons between different notions of privacy
- trade-offs between privacy and utility
We think it will be very valuable to have a forum to unify different perspectives and start a discussion about the relative merits of each approach. The workshop will also serve as a venue for networking people from different communities interested in this problem, and hopefully foster fruitful long-term collaboration.
Submission Instructions
Submissions in the form of extended abstracts must be at most 4 pages long (not including references) and adhere to the NIPS format. We do accept submissions of work recently published or currently under review. Submissions should be anonymized. The workshop will not have formal proceedings, but authors of accepted abstracts can choose to have a link to arxiv or a pdf published on the workshop webpage.
- Submission url: https://easychair.org/conferences/?conf=ppml18
- Submission deadline: October 8, 2018 (11:59pm AoE)
- Notification of acceptance: November 1, 2018
Program Committee
- Pauline Anthonysamy (Google)
- Borja de Balle Pigem (Amazon)
- Keith Bonawitz (Google)
- Emiliano de Cristofaro (University College London)
- David Evans (University of Virginia)
- Irene Giacomelli (Wisconsin University)
- Nadin Kokciyan (King’s College London)
- Kim Laine (Microsoft Research)
- Payman Mohassel (Visa Research)
- Catuscia Palamidessi (Ecole Polytechnique & INRIA)
- Mijung Park (Max Planck Institute for Intelligent Systems)
- Benjamin Rubinstein (University of Melbourne)
- Anand Sarwate (Rutgers University)
- Philipp Schoppmann (HU Berlin)
- Nigel Smart (KU Leuven)
- Carmela Troncoso (EPFL)
- Pinar Yolum (Utrecht University)
- Samee Zahur (University of Virginia)
Organizers
- Adria Gascon (Alan Turing Institute & Edinburgh)
- Niki Kilbertus (MPI for Intelligent Systems & Cambridge)
- Olya Ohrimenko (Microsoft Research)
- Mariana Raykova (Yale)
- Adrian Weller (Alan Turing Institute & Cambridge)
 and compute the second moment matrix
and compute the second moment matrix  . If we want to compute the SVD in a differentially private way, one approach is to add noise
. If we want to compute the SVD in a differentially private way, one approach is to add noise  to the second moment matrix to form
to the second moment matrix to form 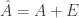 such that
such that 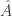 is a differentially private version of
is a differentially private version of  . Then by postprocessing invariance, the SVD of
. Then by postprocessing invariance, the SVD of  -differentially private algorithm? What is wrong with
-differentially private algorithm? What is wrong with  ? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the
? In some application domains, I have found that the notion of a “failure probability” is not compatible with practitioners’t (often lawyer-driven) policy requirements. Concentrated DP and newer concepts still keep the  choice for
choice for 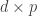 Gaussian matrix $\latex Z$ and settting
Gaussian matrix $\latex Z$ and settting  . This generates a PSD perturbation fo
. This generates a PSD perturbation fo 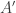 coming from neighboring databases, the cones are not the same. As a trivial example, suppose
coming from neighboring databases, the cones are not the same. As a trivial example, suppose 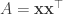 and
and  . Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive.
. Hafiz has written up a more formal description. Because differential privacy requires the support of the output distribution under different inputs to coincide, it is difficult to create a (data-independent) additive perturbation that preserves the PSD property. The exponential mechanism works, but is not additive. is unacceptable.
is unacceptable.