Privacy Preserving Machine Learning
NIPS 2018 Workshop
Montreal, December 8, 2018
Description
This one day workshop focuses on privacy preserving techniques for training, inference, and disclosure in large scale data analysis, both in the distributed and centralized settings. We have observed increasing interest of the ML community in leveraging cryptographic techniques such as Multi-Party Computation (MPC) and Homomorphic Encryption (HE) for privacy preserving training and inference, as well as Differential Privacy (DP) for disclosure. Simultaneously, the systems security and cryptography community has proposed various secure frameworks for ML. We encourage both theory and application-oriented submissions exploring a range of approaches, including:
- secure multi-party computation techniques for ML
- homomorphic encryption techniques for ML
- hardware-based approaches to privacy preserving ML
- centralized and decentralized protocols for learning on encrypted data
- differential privacy: theory, applications, and implementations
- statistical notions of privacy including relaxations of differential privacy
- empirical and theoretical comparisons between different notions of privacy
- trade-offs between privacy and utility
We think it will be very valuable to have a forum to unify different perspectives and start a discussion about the relative merits of each approach. The workshop will also serve as a venue for networking people from different communities interested in this problem, and hopefully foster fruitful long-term collaboration.
Submission Instructions
Submissions in the form of extended abstracts must be at most 4 pages long (not including references) and adhere to the NIPS format. We do accept submissions of work recently published or currently under review. Submissions should be anonymized. The workshop will not have formal proceedings, but authors of accepted abstracts can choose to have a link to arxiv or a pdf published on the workshop webpage.
- Submission url: https://easychair.org/conferences/?conf=ppml18
- Submission deadline: October 8, 2018 (11:59pm AoE)
- Notification of acceptance: November 1, 2018
Program Committee
- Pauline Anthonysamy (Google)
- Borja de Balle Pigem (Amazon)
- Keith Bonawitz (Google)
- Emiliano de Cristofaro (University College London)
- David Evans (University of Virginia)
- Irene Giacomelli (Wisconsin University)
- Nadin Kokciyan (King’s College London)
- Kim Laine (Microsoft Research)
- Payman Mohassel (Visa Research)
- Catuscia Palamidessi (Ecole Polytechnique & INRIA)
- Mijung Park (Max Planck Institute for Intelligent Systems)
- Benjamin Rubinstein (University of Melbourne)
- Anand Sarwate (Rutgers University)
- Philipp Schoppmann (HU Berlin)
- Nigel Smart (KU Leuven)
- Carmela Troncoso (EPFL)
- Pinar Yolum (Utrecht University)
- Samee Zahur (University of Virginia)
Organizers
- Adria Gascon (Alan Turing Institute & Edinburgh)
- Niki Kilbertus (MPI for Intelligent Systems & Cambridge)
- Olya Ohrimenko (Microsoft Research)
- Mariana Raykova (Yale)
- Adrian Weller (Alan Turing Institute & Cambridge)
 where
where  is private and
is private and  is “useful” — the goal is to produce a version of the data which reveals less about
is “useful” — the goal is to produce a version of the data which reveals less about 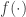 using a protocol for
using a protocol for 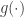 , then
, then  bit XOR doesn’t reduce to an
bit XOR doesn’t reduce to an 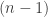 bit XOR. It was a pretty interesting talk, and I learned quite a bit!
bit XOR. It was a pretty interesting talk, and I learned quite a bit!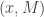 and Bob has
and Bob has  . They both send messages to a third party, Charlie. There is a 0-1 function (predicate)
. They both send messages to a third party, Charlie. There is a 0-1 function (predicate)  such that if
such that if  then Charlie can decode the message
then Charlie can decode the message  . Otherwise, they cannot. An example would be the predicate
. Otherwise, they cannot. An example would be the predicate  . In this case, Alice can send
. In this case, Alice can send 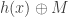 and Bob can send
and Bob can send  for some 2-wise independent hash function, and then Charlie can recover
for some 2-wise independent hash function, and then Charlie can recover  . It really was a very nice talk and pretty understandable even with my own limited background.
. It really was a very nice talk and pretty understandable even with my own limited background.