So you’re going to be presenting at the Annual Allerton Conference on Communication, Control, and Computing, you say? This annual conference, sometimes called the “Burning Man for EE Systems” by the younger set, has a much older pedigree. This year is the 54th anniversary, and you want to make sure you make an impression making sure you dress (your slides) for success! Here are some tips from old hands on how to make sure your talk is the Sun Singer and not the Death of the Last Centaur.
- Library: You landed a slot in the library, the crème-de-la-crème of venues at the Allerton Mansion! There is ample seating, so even a moderate audience may seem sparse. Although your slides will be visible, your voice may be inaudible, especially for those “attendees” who are actually checking Facebook against the back wall. Invest in a stage-acting class or perhaps bring a megaphone.
- Solarium: Afraid that early fall in the Midwest may be a bit chilly? Fear no more, for the Solarium is surrounded by glass and boasts a climate that is more Humboldt than Piatt. Even if the forecast is for rain, beware of light colors on your slides — they will be overwhelmed by the kiss of Phoebus. If the forecast is particularly sunny, consider polarizing the projector and handing out sunglasses for the audience
- Butternut/Pine: Regardless of how esoteric your paper may be, you are nearly guaranteed a packed house: expect your talk to be punctuated by the door opening, a slight breeze filtering in, and the faint sound of light swearing. In order to maximize visibility, try to not obscure the view of your slides. Recommended places to position yourself include on a bookshelf or behind the screen.
- Lower Level: Unlike a horror house, the basement of Allerton Mansion is where the fun is — the pool table and ice maker! Here you will be cool, comfortable, and nigh invisible. For some pre-Halloween fun, bring a flashlight and make your presentation a ghost story! Regardless, make sure your slides only have important information on the top quarter of the screen so that session attendees beyond the first row can get the gist.
- Visitor Center: (Discontinued this year!) In the past, adventurous Allerton attendes would trek across the wild groves and through a manicured garden to the Visitor Center to attend special sessions al fresco (this was a change from the Tent, which may have been more properly au naturel). Hard times on the road make for famished session attendees. Consider offering complementary snacks and beverage to boost attendance.
 : New Jersey driver
: New Jersey driver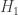 : New York driver
: New York driver be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
 from New Jersey and New York, respectively, I would have to say
from New Jersey and New York, respectively, I would have to say

