It’s confirmed that I will be teaching Detection and Estimation next semester so I figured I would use the blog to conjure up some book recommendations (or even debate, if I can be so hopeful). Some of the contenders:
- Steven M. Kay, Fundamentals of Statistical Signal Processing – Estimation Theory (Vol. 1), Prentice Hall, 1993.
- H. Vincent Poor, An Introduction to Signal Detection and Estimation, 2nd Edition, Springer, 1998.
- Harry L. Van Trees, Detection, Estimation, and Modulation Theory (in 4 parts), Wiley, 2001 (a reprint).
- M.D. Srinath, P.K. Rajasekaran, P. K. and R. Viswanathan, Introduction to Statistical Signal Processing with Applications, Prentice Hall, 1996.
Detection and estimation is a fundamental class for the ECE graduate curriculum, but these “standard” textbooks are around 20 years old, and I can’t help but think there might be more “modern” take on the subject (no I’m not volunteering). Venu Veeravalli‘s class doesn’t use a book, but just has notes. However, I think the students at Rutgers (majority MS students) would benefit from a textbook, at least as a grounding.
Srinath et al. is what my colleague Narayan Mandyam uses. Kay is what I was leaning to before (because it seems to be the most widely used), but Poor’s book is the one I read. I think I am putting up the Van Trees as a joke, mostly. I mean, it’s a great book but I think a bit much for a textbook. So what do the rest of you use? Also, if you are teaching this course next semester, perhaps we can share some ideas. I think the curriculum might be ripe for some shaking up. If not in core material, at least in the kinds of examples we use. For example, I’m certainly going to cover differential privacy as a connection to hypothesis testing.
 : New Jersey driver
: New Jersey driver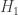 : New York driver
: New York driver be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
 from New Jersey and New York, respectively, I would have to say
from New Jersey and New York, respectively, I would have to say
