I’ll round out the end of my ISIT blogging with very brief takes on a few more papers. I took it pretty casually this year in terms of note taking, and while I attended many more talks, my notes for most of them consist of a title and a star next to the ones where I want to look at the paper more closely. That’s probably closer to how most people attend conferences, only they probably use the proceedings book. I actually ended up shredding the large book of abstracts to use as bedding for my vermicompost (I figured they might appreciate eating a little Turkish paper for a change of diet).
On Connectivity Thresholds in Superposition of Random Key Graphs on Random Geometric Graphs
B Santhana Krishnan (Indian Institute of Technology, Bombay, India); Ayalvadi Ganesh (University of Bristol, United Kingdom); D. Manjunath (IIT Bombay, India)
This looked at a model where you have a random geometric graph (RGG) together with a uniformly chosen random subset 

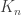

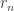
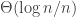
Secure Network Coding for Distributed Secret Sharing with Low Communication Cost
Nihar B Shah (University of California at Berkeley, USA); K. v. Rashmi (University of California at Berkeley, USA); Kannan Ramchandran (University of California at Berkeley, USA)
This paper was on secret sharing — a dealer wants to distribute 


Conditional Equivalence of Random Systems and Indistinguishability Proofs
Ueli Maurer (ETH Zurich, Switzerland)
This was scheduled to be in the same session as my paper with Vinod, but was moved to an earlier session. Maurer’s “programme” as it were, is to think about security via three kinds of systems — real systems with real protocols and pseudorandomness, idealized systems with real protocols but real randomness, and perfect systems which just exist on paper. The first two are trivially indistinguishable from a computational perspective, and the goal is to show that the last two are information-theoretically indistinguishable. This conceptual framework is actually useful for me to separate out the CS and IT sides of the security design question. This paper tried to set up a framework in which there is a distinguisher D which tries to make queries to two systems and based on the answers has to decide if they are different or not. I think if you’re interested in sort of a systems-theoretic take on security you should take a look at this.
Tight Bounds for Universal Compression of Large Alphabets
Jayadev Acharya (University of California, San Diego, USA); Hirakendu Das (University of California San Diego, USA); Ashkan Jafarpour (UCSD, USA); Alon Orlitsky (University of California, San Diego, USA); Ananda Theertha Suresh (University of California, San Diego, USA)
The main contribution of this paper was to derive bounds on compression of patterns of sequences over unknown/large alphabets. The main result is that the worst case pattern redundancy for i.i.d. distributions is basically 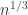
To Surprise and Inform
Lav R. Varshney (IBM Thomas J. Watson Research Center, USA)
Lav talked about communication over a channel where the goal is to communicate subject to a constraint on the Bayesian surprise 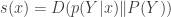


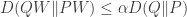
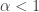 , so the idea is to get bounds on
, so the idea is to get bounds on .
.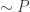 from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item
from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item  . This paper looks at the number of guesses one needs if
. This paper looks at the number of guesses one needs if  is uniform on the typical set according to
is uniform on the typical set according to 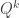 conditioned on
conditioned on 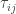 for the
for the  to infect
to infect  if
if  for a code, the encoder wiring could be messed up and bits could be flipped or erased when parities are being computed. The resulting error model can’t just be folded into the channel. Furthermore, a small amount of error in the encoder (in just the right place) could be catastrophic. They focus just on edge erasures in this problem and derive a new distance metric between codewords that helps them characterize the maximum number of erasures that an encoder can tolerate. They also look at a random erasure model.
for a code, the encoder wiring could be messed up and bits could be flipped or erased when parities are being computed. The resulting error model can’t just be folded into the channel. Furthermore, a small amount of error in the encoder (in just the right place) could be catastrophic. They focus just on edge erasures in this problem and derive a new distance metric between codewords that helps them characterize the maximum number of erasures that an encoder can tolerate. They also look at a random erasure model.![\{p_i : i \in [n]\}](https://s0.wp.com/latex.php?latex=%5C%7Bp_i+%3A+i+%5Cin+%5Bn%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . For some given
. For some given ![p \in [\epsilon,1-\epsilon]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B%5Cepsilon%2C1-%5Cepsilon%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 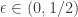 , each coin is “heavy” (
, each coin is “heavy” (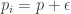 ) with probability
) with probability  and “light” (
and “light” (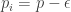 ) with probability
) with probability 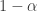 . The goal is to use a sequential flipping strategy to find a heavy coin with probability at least
. The goal is to use a sequential flipping strategy to find a heavy coin with probability at least  .
.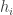 heads and
heads and  tails, then the likelihood ratio is
tails, then the likelihood ratio is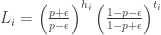
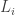 so far (breaking ties arbitrarily).
so far (breaking ties arbitrarily). . These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
. These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which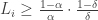
 heads and tails for a coin $i$,
heads and tails for a coin $i$,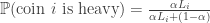 ,
,