I anticipate I will be doing a fair bit more reading in the future, due to the new job and personal circumstances. However, I probably won’t write more detailed notes on the books. This blog should be a rapidly mixing random walk, after all.
Embassytown (China Miéville) : a truly bizarre novel set on an alien world in on which humans have an Embassy but can only communicate with the local aliens in a language which defies easy description. Ambassadors come in pairs, as twins — to speak with the Ariekei they must both simultaneously speak (in “cut” and “turn”). The Ariekei’s language does not allow lying, and they have contests in which they try to speak falsehoods. However, events trigger a deadly change (I don’t want to give it away). Philosophically, the book revolves a lot around how language structures thought and perception, and it’s fascinating if you like to think about those things.
Chop Suey: A Cultural History of Chinese Food in the United States (Andrew Coe) : an short but engaging read about how Chinese food came to the US. The book starts really with Americans in China and their observations on Chinese elite banquets. A particular horror was that the meat came already chopped up — no huge roasts to carve. Chapter by chapter, Coe takes us through the railroad era through the 20s, the mass-marketing of Chinese food and the rise of La Choy, through Nixon going to China. The book is full of fun tidbits and made my flights to and from Seattle go by quickly.
The Thousand Autumns of Jacob de Zoet: A Novel (David Mitchell) : I really love David Mitchell’s writing, but this novel was not my favorite of his. It was definitely worth reading — I devoured it — but the subject matter is hard. Jacob de Zoet is a clerk in Dejima, a Dutch East Indies trading post in 19th century Japan. There are many layers to the story, and more than a hint of the grotesque and horrific, but Mitchell has an attention to detail and a mastery with perspective that really makes the place and story come alive.
Air (Geoff Ryman) : a story about technological change, issues of the digital divide, economic development, and ethnic politics, set in a village in fictional Karzistan (looks like Kazakhstan). Air is like having mandatory Internet in your brain, and is set to be deployed globally. During a test run in the village, Chung Mae, a “fashion expert,” ends up deep into Air and realizes that the technology is going to change their lives. She goes about trying (in a desperate, almost mad way) to tell her village and bring them into the future before it overwhelms them. There’s a lot to unpack here, especially in how technology is brought to rural communities in developing nations, how global capital and the “crafts” market impacts local peoples, and the dynamics of village social orders. It’s science fiction, but not really.
The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy (Sharon Bertsch McGrayne) : an engaging read about the history of Bayesian ideas in statistics. It reads a bit like an us vs. them, the underdog story of how Bayesian methods have overcome terrible odds (prior beliefs?) to win the day. I’m not sure I can give it as enthusiastic a review as Christian Robert, but I do recommend it as an engaging popular nonfiction read on this slice in the history of modern statistics. In particular, it should be entertaining to a general audience.
Dangerous Frames: How Ideas about Race and Gender Shape Public Opinion (Nicholas J.G. Winter) : the title says most of it, except it’s mostly about how ideas about race and gender shape white public opinion. The basic theoretical structure is that there are schemas that we carry that help us interpret issues, like a race schema or a gender schema. Then there are frames or narratives in which issues are put. If the schema is “active” and an issue is framed in a way that is concordant with the schema, then people’s opinions follow the schema, even if the issue is not “about” race or gender. This is because people reason analogically, so they apply the schema if it matches. To back up the theory, Winter has some experiments, both of the undergrads doing psych studies type as well as survey data, to show that by reframing certain issues people’s “natural” beliefs can be skewed by the schema that they apply. The schemas he discusses are those of white Americans, mostly, so the book feels like a bit of an uncomfortable read because he doesn’t really interrogate the somewhat baldly racist schemas. The statistics, as with all psychological studies, leaves something to be desired — I take the effects he notices at a qualitative level (as does he, sometimes).

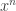


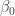 , then using Bayesian inference the posterior should concentrate around
, then using Bayesian inference the posterior should concentrate around  differential privacy on the utility functions of the users.
differential privacy on the utility functions of the users.