Differentially Private Filtering and Differentially Private Kalman Filtering
Jerome Le Ny, George J. Pappas
These papers apply the differential privacy model to classical signal processing and look at the effect of adding noise before filtering and summing versus adding noise after filtering and summing. The key is that the operations have to be causal, I think — we usually think about differential privacy as operating offline or online in very restricted settings, but here the signals are coming in as time series.
Finite sample posterior concentration in high-dimensional regression
Nate Strawn, Artin Armagan, Rayan Saab, Lawrence Carin, David Dunson
They study ultra high-dimensional linear regression (cue guitars and reverb) in the “large p, small n” setting. The goal is to get a Bernstein-von Mises type theorem — e.g. assuming the data comes from a linear model 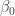
Identifying Users From Their Rating Patterns
José Bento, Nadia Fawaz, Andrea Montanari, and Stratis Ioannidis
This is a paper about recommender systems as part of the 2011 CAMRa challenge. They look at the problem of re-identification of users in this data and show that looking at the time stamps of movie ratings is much more useful than looking at the rating values. This suggests to me that people should use a masking system like Anant and Parv’s “Incentivizing Anonymous ‘Peer-to-Peer’ Reviews” (P. Venkitasubramaniam and A. Sahai, Allerton 2008) paper.
<a href="http://arxiv.org/abs/1207.4084v1"Mechanism Design in Large Games: Incentives and Privacy
Michael Kearns, Mallesh M. Pai, Aaron Roth, Jonathan Ullman
This proposes a variant of differential privacy which they call joint differential privacy and look at mechanism designs that satisfy privacy and are incentive compatible. At first glance, these should be incompatible, since the latter implies “revealing the truth.” The model is one in which each agent has a finite set of actions but its own payoff/value is private. This is somewhat out of my area, so I can’t really get the nuances of what’s going on here, but a crucial assumption here is that there are a large number of agents. Joint differential privacy seems to be a form of 
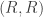 , if the first (resp. second) defects (D) they are
, if the first (resp. second) defects (D) they are 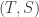 (resp.
(resp. 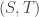 ) and if they both defect then
) and if they both defect then 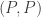 . The usual conditions are
. The usual conditions are  to keep it interesting.
to keep it interesting.