I was a somewhat inconsistent note-taker here. Because a lot of the talks I attended were sufficiently out-of-area for me that I didn’t get the context for the work, I often found myself jotting a few “look at this later” pointers to myself rather than actual ideas from the talk.
First, the plenaries: Eric Horvitz, Michael Kearns, and Michael Jordan. Horvitz talked about how we’ve made a lot of progress in machine learning but there’s more work to be done in bringing humans back into the loop. Examples include developing semantics for what features mean, how to visualize the results, adding humans into the loop (e.g. active learning or interactive settings), crowdsourcing, and building tools that are sensitive to human cognitive limitations, like detecting and informing people of “surprising events,” which involves knowing what surprising means. He also announced a new data set, COCO for “common objects in context” (not Cocoa Puffs) which has around 300k-400k images and lots of annotations. The goal was to build al library of objects that a 4-year-old can recognize. Can a computer?
I honestly was a little too zonked/jetlagged to understand Michael Kearns’ talk, which was on challenges in algorithmic trading. He was focused on problems that brokers face, rather than the folks who are holding the risk. Michael Jordan gave a variant on a talk I’ve seen him give in the last few plenary/big talks I’ve seen: computation, statistics, and big data. The three examples he talked about were local differential privacy, bounds for distributed estimation, and the bag of little bootstraps.
As far as the research talks go, here are a few from the first day:
- Robust Principal Component Analysis with Complex Noise(Qian Zhao; Deyu Meng; Zongben Xu; Wangmeng Zuo; Lei Zhang): This paper interpreted the Robust PCA problem (given
 where
where  is low-rank and
is low-rank and  is sparse, recover ) in terms of MAP inference. The solution generally looks like a nuclear-norm plus
is sparse, recover ) in terms of MAP inference. The solution generally looks like a nuclear-norm plus 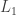 regularization, which they claim implies a kind of Laplace-like model for the noise. They build a generative model and then change the distributions around to get different noise models.
regularization, which they claim implies a kind of Laplace-like model for the noise. They build a generative model and then change the distributions around to get different noise models.
- Discriminative Features via Generalized Eigenvectors (Nikos Karampatziakis; Paul Mineiro): This was on how to learn features that are discriminative in a multiclass setting while still being somewhat efficient. The main idea was to look at correlations in the existing features via the tensor
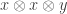 where
where  are the features and
are the features and  are the labels, and to then find generalized eigenvalues and eigenvectors by looking for vectors
are the labels, and to then find generalized eigenvalues and eigenvectors by looking for vectors  that maximize (for a given
that maximize (for a given  the ratio
the ratio ![\frac{ \mathbb{E}[ (v^{\top} x)^2 | y = i] }{ \mathbb{E}[ (v^{\top} x)^2 | y = j] }](https://s0.wp.com/latex.php?latex=%5Cfrac%7B+%5Cmathbb%7BE%7D%5B+%28v%5E%7B%5Ctop%7D+x%29%5E2+%7C+y+%3D+i%5D+%7D%7B+%5Cmathbb%7BE%7D%5B+%28v%5E%7B%5Ctop%7D+x%29%5E2+%7C+y+%3D+j%5D+%7D&bg=ffffff&fg=333333&s=0&c=20201002) . This nonlinearity is important for reasons which I wasn’t entirely sure about.
. This nonlinearity is important for reasons which I wasn’t entirely sure about.
- Randomized Nonlinear Component Analysis (David Lopez-Paz; Suvrit Sra; Alex Smola; Zoubin Ghahramani; Bernhard Schoelkopf): I really enjoyed this talk — basically the idea is kernel versions of PCA and CCA have annoyingly large running times. So what they do here is linearize the kernel using sampling and then do some linear component analysis on the resulting features. The key tool is to use Matrix Bernstein inequalities to bound the kernel approximations.
- Memory and Computation Efficient PCA via Very Sparse Random Projections (Farhad Pourkamali Anaraki; Shannon Hughes): This talk was on efficient approximations to PCA for large data sets, but not in a streaming setting. The idea was, as I recall, that you have big data sets and different sites. Each site takes a very sparse random projection of its data (e.g. via a random signed Bernoulli matrix) and then these get aggregated via an estimator. They show that the estimator is unbiased and the variance depends on the kurtosis of the distribution of elements in the projection matrix. One thing that was interesting to me is that the covariance estimate has bias term towards the canonical basis, which is one of those facts that makes sense after you hear it.
- Concept Drift Detection Through Resampling (Maayan Harel; Shie Mannor; Ran El-Yaniv; Koby Crammer): This talk was sort of about change-detection, but not really. The idea is that a learning algorithm sees examples sequentially and wants to tell if there is a significant change in the expected risk of the distribution. The method they propose is a sequential permutation test — the challenge is that a gradual change in risk might be hard to detect, and the number of possible hypotheses to consider grows rather rapidly. I got some more clarification from Harel’s explanation at the poster, but I think this is one where reading the paper will make it clearer.
Noted without notes, but I enjoyed the posters (sometimes I read them since the presenter was not around):
- An Asynchronous Parallel Stochastic Coordinate Descent Algorithm (Ji Liu; Steve Wright; Christopher Re; Victor Bittorf; Srikrishna Sridhar)
- Clustering in the Presence of Background Noise (Shai Ben-David; Nika Haghtalab)
- Demystifying Information-Theoretic Clustering (Greg Ver Steeg; Aram Galstyan; Fei Sha; Simon DeDeo)
- Consistency of Causal Inference under the Additive Noise Model (Samory Kpotufe; Eleni Sgouritsa; Dominik Janzing; Bernhard Schoelkopf)
- Concentration in unbounded metric spaces and algorithmic stability (Aryeh Kontorovich)
- Hard-Margin Active Linear Regression (Zohar Karnin; Elad Hazan)
- Heavy-tailed regression with a generalized median-of-means (Daniel Hsu; Sivan Sabato)


