I’m headed to NIPS next week. Via my (soon to be ex-) colleague Dhruv Batra comes this fun visualization by Andrej Karpathy of the topics of papers, clustered by an LDA model.
Monthly Archives: November 2012
The things we know we don’t know
As a theoretical engineer, I find myself getting lulled into the trap of what I now starting to call “lazy generalization.” It’s a form of bland motivation that you often find at the beginning of papers:
Sensor networks are large distributed collections of low-power nodes with wireless radios and limited battery power.
Really? All sensor networks are like this? I think not. Lots of sensor networks are wired (think of the power grid) but still communicate wirelessly. Others communicate through wires. This is the kind of ontological statement that metastasizes into the research equivalent of a meme — 3 years after Smart Dust appears, suddenly all papers are about dust-like networks, ignoring the vast range of other interesting problems that arise in other kinds of “sensor networks.”
Another good example is “it is well known that most [REAL WORLD THING] follows a power law,” which bugs Cosma to no end. We then get lots of papers papers which start with something about power laws and then proceed to analyze some algorithms which work well on graphs which have power law degree distributions. And the later we get statements like “all natural graphs follow power laws, so here’s a theory for those graphs, which tells us all about nature.”
Yet another example of this is sparsity. Sparsity is interesting! It lets you do a lot of cool stuff, like compressed sensing. And it’s true that some real world signals are approximately sparse in some basis. However, turn the crank and we get papers which make crazy statements approximately equal to “all interesting signals are sparse.” This is trivially true if you take the signal itself as a basis element, but in the way it’s mean (e.g. “in some standard basis”), it is patently false.
So why is are these lazy generalization? It’s a kind of fallacy which goes something like:
- Topic A is really useful.
- By assuming some Structure B about Topic A, we can do lots of cool/fun math.
- All useful problems have Structure B
Pattern matching, we get A = [sensor networks, the web, signal acquisition], and B = [low power/wireless, power laws, sparsity].
This post may sound like I’m griping about these topics being “hot” — I’m not. Of course, when a topic gets hot, you get a lot of (probably incremental) papers all over the place. That’s the nature of “progress.” What I’m talking about is the third point. When we go back to our alabaster spire of theory on top of the ivory tower, we should not fall into the same trap of saying that “by characterizing the limits of Structure B I have fundamentally characterized Topic A.” Maybe that’s good marketing, but it’s not very good science, I think. Like I said, it’s a trap that I’m sure I’m guilty of stepping into on occasion, but it seems to be creeping into a number of things I’ve been reading lately.
Readings
Snuff [Terry Pratchett] : this was standard Discworld stuff, but I found it a little below-average. I’m finicky that way though.
Snakes Can’t Run [Ed Lin] : a follow-up to This Is A Bust, this book is about human smuggling in New York Chinatown in the 70s. Recommended if you like thing Asian and mysterious.
Shark’s Fin and Sichuan Pepper: A Sweet-Sour Memoir of Eating in China [Fuschia Dunlop] : I found this memoir to be engaging but it’s definitely got that feel of “Western person’s observations about China.” Dunlop is more aware of her situation as outsider/observer, but sometimes its hard to shake that narrative vibe. That being said, you should definitely read this if you want to know more about Chinese cuisines.
Among Others [Jo Walton] : it won a Nebula and a Hugo and I could see why. This is a really sharply observed and narrated coming-of-age story about a high school girl who is not part of the “main crowd” and finds her solace in voraciously reading all of the SciFi/Fantasy novels she can get her hands on. Really lovely writing.
The Lost Soul of Higher Education [Ellen Schrecker] : a pretty sobering read with a lot of historical background on the state of academic freedom, the corporatization of the university system, and possible ramifications for the future of the US. It was a bit depressing but well worth reading.
One Day in the Life of Ivan Denisovich [Aleksandr Solzhenitsyn] : this is Solzhenitsyn’s first book, a first-person narrative of one person’s life in a Stalinist labor camp. It really brings the grimness of the place alive — Cool Hand Luke’s prison camp had nothing on this. They’re worth comparing, I think.
Linkage : Black Friday edition
This is an amazing video that makes me miss the Bay Area. (via Bobak Nazer)
Also via Bobak, we’re number 8 and 10!
Since it’s holiday season, I figured it’s time to link to some profanity-laden humor about the holidays. For the new, The Hater’s Guide to the Williams-Sonoma Catalog, and the classic It’s Decorative Gourd Season….
A Game of Food Trucks. (via MetaFilter)
Larry Wasserman takes on the Bayesian/Frequentist debate.
LCD Soundsystem + Miles Davis youtube mashup.
My friend Erik, who started the Mystery Brewing Company, has a blog called Top Fermented. He is now starting a podcast, which also has an RSS feed.
Johnson-Lindenstrauss, Restricted Isometry (RIP), for-each vs for-all, and all that
The Johnson-Lindenstrauss lemma shows how to project points in much lower dimension without significant distortion of their pairwise Euclidean distances.
Say you have n arbitrary vectors 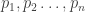

Use a fat random (normalized) Gaussian matrix of dimensions 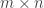
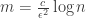
to project the points in m dimensions.
Then, with probability at least 1/2, the projected points 
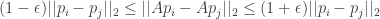
This is quite remarkable since we reduced the dimension from 

This is a very fat matrix.

A number of other matrices beyond Gaussian have been shown to also work with similar guarantees.
The Johnson-Lindenstrauss lemma sounds similar to the Restricted Isometry Property (RIP).
A fat
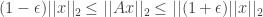
for all vectors 

This means that the matrix A does not distort the 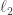
As before, well-known results have shown that random Gaussian matrices satisfy RIP with high probability if we set

To understand the similarities and differences between RIP and JL, we need to see how these results are proven. The central question is how fat random matrices distort the length of vectors and with what probability.
All known proofs of JL (for each matrix family) start with a lemma that deals with one fixed vector:
Lemma 1:
For each given vector
![Pr[ (1-\epsilon) ||x||_2 \leq ||Ax||_2 \leq (1+\epsilon) ||x||_2] \geq 1- P_{fail}(m,n) \quad (1)](https://s0.wp.com/latex.php?latex=Pr%5B+%281-%5Cepsilon%29+%7C%7Cx%7C%7C_2+%5Cleq+%7C%7CAx%7C%7C_2+%5Cleq+%281%2B%5Cepsilon%29+%7C%7Cx%7C%7C_2%5D+%5Cgeq+1-+P_%7Bfail%7D%28m%2Cn%29+%5Cquad+%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
The key issue is between for all versus for each vector quantifiers.
If we first fix the vector and throw the matrix randomly, this is much easier than promising something for a random matrix that once realized, works w.h.p. for all vectors.
Clearly, if first realize the matrix, there are certainly vectors where lemma 1 cannot hold: since the matrix is fat, it has a nullspace so there are nonzero vectors that have 
How small we can make 
To prove JL for some family of matrices we need to make 
If we have lemma 1 with this guarantee, we just do a union bound over all 

It turns out that for Gaussian iid matrices, if you make 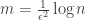
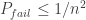
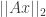


To prove RIP, exactly the same recipe can be followed: first prove Lemma 1 for one vector and then do a union bound over all 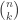


The general recipe emerges. Say you want to prove a good property for all hairy vectors.
First show that for each fixed vector a random matrix has the good property with probability at least 
Then ensure 
Finally, a union bound establishes the property for all hairy vectors.
i’m in ur protocolz, jammin ur cellphonez
Krish Eswaran sent me a story about how a group at Virgina Tech described how LTE networks are susceptible to a certain kind of jamming strategy:
“An example strategy would be to target specific control or synchronization signals, in order to increase the geographic range of the jammer and better avoid detection,” the Wireless @ Virginia Tech research group said in a filing (PDF) submitted to the National Telecommunications and Information Administration. “The availability of low-cost and easy to use software-defined radios makes this threat even more realistic.”
Color me unsurprised! For my PhD, I studied arbitrarily varying channels (AVCs), which are information-theoretic models for communication against adversarial interference. There are a couple of design insights one can distill from considering the AVC model:
- Separating protocol and payload makes schemes susceptible to spoofing.
- Lack of synchronization/coordination between sender and receiver can be a real problem in adversarial settings.
Here we have a case where the protocol is easy to spoof/disrupt, essentially because the control information in unprotected.
This separation between control information and payload is often suboptimal in other senses. See, for example, Tchamkerten, Chandar and Wornell.
Linkage
New(ish) policies at the NSF — read up if you are planning on writing some grants! h/t to Helena, who sent this in aaaaages ago.
I’m not sure I agree that these are the 10 must-listen, but it’s something at least.
This article on Jonah Lehrer is quite interesting. I think there are some things to be learned here for academic writers as well…
I forgot to add a link to Suhas Mathur has a blog, sorry!
“bibimbap is a tool to import BibTeX entries from various sources. It runs in the console and is designed to be simple and fast. bibimbap is simply the easiest way to manage your BibTeX bibliographies. Be advised that it still won’t read the papers for you, though.” — looks like it could be awesome. h/t to Manu.
Problems in modeling Illumina sequencing
About a year ago I started collaborating with a friend in the Armbrust Lab at the University of Washington on some bioinformatics problems, and as a part of that I am trying to give myself a primer on sequencing technologies and how they work. I came across this video recently, and despite its atrocious music and jargonized description, I actually found it quite helpful in thinking about how this particular sequencing technology works:
- Acoustic waves shatter the DNA.
- Things (ligases) get attached to the end.
- The fragments get washed over a “lawn” and the ligases stick the sequences to the lawn.
- The strands get amplified into larger spots.
- Single nucleotides with phosphorescent tags are washed on, they are hit with a laser to reveal the color, the tag is sheared, and then the next nucleotide is washed on.
A simple model for the data we get is to say that a position in the genome is selected uniformly at random, and then the read is the sequence of size 
- The places at which the DNA fragments are not uniformly distributed — in fact, they should be sequence-dependent.
- The ligases may have some preferential attachment characteristics. Ditto for the oligos on the lawn in the flowcell.
- The amplification may be variable, spot by spot. This will affect the brightness of the flash and therefore the reliability of the read assessment.
- The ability of single nucleotides to bind will vary as more and more bases are read, so the gain in the optical signal (or noise) will vary as the read goes on.
Some of these effects are easier to model than others, but what is true from the real data is that these variations in the technology can cause noticeable effects in the data that deviate from the simple model. More fun work to do!
