The ITA Workshop finished up today, and I know I promised some blogging, but my willpower to take notes kind of deteriorated during the week. For today I’ll put some pointers to talks I saw today which were interesting. I realize I am heavily blogging about Berkeley folks here, but you know, they were interesting talks!
Nadia Fawaz talked about differential privacy for continuous observations : in this model you see 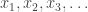 causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for
causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for  past values, and one in which the privacy constraint decays and expires after a window of time , so that values time steps in the past do not have to be protected at all. This yields some differences in the privacy-utility tradeoff in terms of the accuracy of computing the function.
past values, and one in which the privacy constraint decays and expires after a window of time , so that values time steps in the past do not have to be protected at all. This yields some differences in the privacy-utility tradeoff in terms of the accuracy of computing the function.
David Tse gave an interesting talk about sequencing DNA via short reads as a communication problem. I had actually had some thoughts along these lines earlier because I am starting to collaborate with my friend Tony Chiang on some informatics problems around next generation sequencing. David wanted to know how many (noiseless) reads  you need to take of a genome of of length
you need to take of a genome of of length  using reads of length
using reads of length  . It turns out that the correct scaling in this model is
. It turns out that the correct scaling in this model is  . Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still.
. Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still.
Michael Jordan talked about the “big data bootstrap” (paper here). You have  data points, where is huge. The idea is to subsample a set of size
data points, where is huge. The idea is to subsample a set of size  and then do bootstrap estimates of size on the subsample. I have to read the paper on this but it sounds fascinating.
and then do bootstrap estimates of size on the subsample. I have to read the paper on this but it sounds fascinating.
Anant Sahai talked about how to look at some decentralized linear control problems as implicitly doing some sort of network coding in the deterministic model. One way to view this is to identify unstable modes in the plant as communicating with each other using the controllers as relays in the network. By structurally massaging the control problem into a canonical form, they can make this translation a bit more formal and can translate results about linear stabilization from the 80s into max-flow min-cut type results for network codes. This is mostly work by Se Yong Park, who really ought to have a more complete webpage.
Paolo Minero talked about controlling a linear plant over a rate-limited communication link whose capacity evolves according to a Markov chain. What are the conditions on the rate to ensure stability? He made a connection to Markov jump linear systems that gives the answer in the scalar case, but the necessary and sufficient conditions in the vector case don’t quite match. I always like seeing these sort of communication and control results, even though I don’t work in this area at all. They’re just cool.
There were three talks on consensus in the morning, which I will only touch on briefly. Behrouz Touri gave a talk about part of his thesis work, which was on the Hegselman-Krause opinion dynamics model. It’s not possible to derive a Lyapunov function for this system, but he found a time-varying Lyapunov function, leading to an analysis of the convergence which has some nice connections to products of random stochastic matrices and other topics. Ali Jadbabaie talked about work with Pooya Molavi on non-Bayesian social learning, which combines local Bayesian updating with DeGroot consensus to do distributed learning of a parameter in a network. He had some new sufficient conditions involving disconnected networks that are similar in flavor to his preprint. José Moura talked about distributed Kalman filtering and other consensus meets sensing (consensing?) problems. The algorithms are similar to ones I’ve been looking at lately, so I will have to dig a bit deeper into the upcoming IT Transactions paper.
