I’m doggedly completing these notes because in a fit of ambition I actually started posts for each of the workshop days and now I feel like I need to finish it up. Day 3 was a day of differential privacy: Adam Smith, Cynthia Dwork, and Kamalika Chaudhuri.
Adam gave a tutorial on differential privacy that had a bit of a different flavor from tutorials I have seen before (and given). He started out by highlighting a taxonomy of potential attacks on released data to make a distinction between re-identification, reconstruction, membership, and correlation inferences before going into the definitions, composition theory, Bayesian interpretation, and so on. With the attacks, he focused a bit more on the reconstruction story. The algorithms view of things (as I get it) is to think of, say, an LP relaxation of a combinatorial problem: you solve the LP and round the solution to integers and prove that it’s either correct or close to correct. This has more connections to things we think about in information theory (e.g. compressed sensing) but the way of stating the problem was a bit different. He also described the Homer et al. attack on GWAS. The last part of his talk was on multiplicative weights and algorithms for learning distributions over the data domain, which I think got a bit hairy for the IT folks who hadn’t seen MW before. This made me wonder if these connections between mirror descent on the simplex, information projections, and other topics can be taught in a “first principles” way that doesn’t require you to have a lot of familiarity with one interpretation of the method before bridging to another.
Cynthia gave a talk on false discovery control and how to use differential privacy ideas in a version of the Benjamini-Hochberg BHq procedure for controlling the false discovery rate. A key primitive is the the report noisy argmax procedure, which gives the index of the argmax but not its value (which would entail a further privacy loss). Since most people are not familiar with FDR control, she spent a lot of her talk on that and so the full details of the private version were deferred to the paper. I covered FDR in my detection and estimation class partly from some of the extra attention it has received in the privacy workshops over the last few years.
Kamalika’s talk was on a model for privacy when data may be correlated between individuals. This involves using the Pufferfish model for privacy in which there is an explicit class of probability distribution on parameters and a set of explicit secrets which the algorithm wants to obfuscate: the differential privacy guarantee should hold for the output distribution of the mechanism conditioned on any valid data distribution and any pair of secrets. Since the class of data distributions is arbitrary, we can also consider joint distributions on individuals’ data — if the distribution class has some structure, then there might be a hope to efficiently produce an output of a function. She talked about using the 
 where
where  is private and
is private and  is “useful” — the goal is to produce a version of the data which reveals less about
is “useful” — the goal is to produce a version of the data which reveals less about 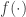 using a protocol for
using a protocol for 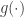 , then
, then  bit XOR doesn’t reduce to an
bit XOR doesn’t reduce to an 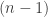 bit XOR. It was a pretty interesting talk, and I learned quite a bit!
bit XOR. It was a pretty interesting talk, and I learned quite a bit!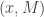 and Bob has
and Bob has  . They both send messages to a third party, Charlie. There is a 0-1 function (predicate)
. They both send messages to a third party, Charlie. There is a 0-1 function (predicate)  such that if
such that if  then Charlie can decode the message
then Charlie can decode the message  . Otherwise, they cannot. An example would be the predicate
. Otherwise, they cannot. An example would be the predicate  . In this case, Alice can send
. In this case, Alice can send 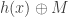 and Bob can send
and Bob can send  for some 2-wise independent hash function, and then Charlie can recover
for some 2-wise independent hash function, and then Charlie can recover  . It really was a very nice talk and pretty understandable even with my own limited background.
. It really was a very nice talk and pretty understandable even with my own limited background.