There’s a certain set of sentiments which undergird a lot of thinking in engineering, and especially engineering about data. You want a method which has good performance “on average” over the population. The other extreme is worst-case, but there are things you can only do in the average case. By focusing on average-case gain, you get a kind of “the needs of the many outweigh the needs of the few” way of thinking about the world.

The needs of the many outweigh the needs of the one… or the few?
Now in the abstract land of mathematical models and algorithms, this might seem like a reasonable principle — if you have to cram everything into a single population utility function you might as well then optimize that. However, this gets messier when you start implementing it in the real world (unless of course you’re an economist of a certain stripe). The needs of the many are often the needs of the more powerful or dominant groups in society. The needs of the few are perhaps those who have been historically marginalized or victimized. Extolling the benefits to the many is often taking a stand for the powerful against the weak. It’s at best deeply insensitive.
Two instances of this have appeared on the blogosphere recently. Scott Aaronson blogged recently about MIT’s decision to take down Walter Lewin’s online videos after Lewin was found to have sexually harassed students in connection with the course. Scott believes that depriving students of Lewin’s materials is a terrible outcome, even (possibly) if he were a murderer. Ignoring the real hurt and trauma felt by those who are affected by Lewin’s actions is an exercise in privilege — because he is not hurt by it, he values the “the good of the many” trumping the “good of the few.”
The whole downplaying of sexual harassment as being somehow “not serious” enough to warrant a serious response (or that the response “makes the most dramatic possible statement about a broader social issue”) in fact trivializes the whole experience of sexual violence. Indeed, by this line of argument, because the content created by Lewin is so valuable, it may be ok to keep online even “had [he] gone on a murder spree.” The subtext of this is “as opposed to merely harassed some women.” I recommend reading Priya Phadnis on this case — she comes to a very different conclusion, namely that special pedestal that we put Walter Lewin on is itself the problem. Being able to downplay the female victims’ claims is exercising the sort of privilege that members of the male professoriat (myself included) indulge in overtly, covertly, and inadvertently. If STEM has a gender problem, it’s in a large part because we do not pay attention to the ways in which our words and actions reinforce existing tropes.
The second post was by Lance Fornow on dying languages in response to an op-ed by John McWhorter on why we should care about language diversity. Lance thinks that speaking a common language is a good thing:
I understand the desire of linguists and social scientists to want to keep these languages active, but to do so may make it harder for them to take advantage of our networked society. Linguists should study languages but they shouldn’t interfere with the natural progression. Every time a language dies, the world gets more connected and that’s not a bad thing.
I guess those poor bleeding-heart social scientists don’t understand that those languages are dying for a good reason. The good of the many — everyone speaking English, the dominant language — outweighs the good of the few. This attitude again speaks from a place of privilege and power, and it reinforces a kind cultural superiority (although I am sure Lance doesn’t think of it that way). Indeed, in many parts of the world, there is and continues to be “a strong reason to learn multiple languages.” By casually (and incorrectly) dismissing the importance of linguistic diversity, such a statement reinforces a chauvinist view of the relationship between language and technology.
We start with desirable outcomes: free quality educational materials that lower the barrier to access or speaking a common language to help facilitate communication and cooperation. By choosing to focus on those outcomes and their benefits to the many, we value their well-being and delegitimize the harm done to others. If we furthermore are speaking from a position of power, our privilege reinforces stigmas, casting a value judgement on the rights, experiences, and beliefs of the few. It’s something to be careful about.

 statistic (from the paper “Prediction and entropy of printed English”), which is essentially the empirical conditional entropy of the current symbol conditioned on the past symbols. They compute:
statistic (from the paper “Prediction and entropy of printed English”), which is essentially the empirical conditional entropy of the current symbol conditioned on the past symbols. They compute:
 and
and  are the number of di-grams and un-grams, respectively. Why normalize? The statistic
are the number of di-grams and un-grams, respectively. Why normalize? The statistic 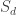 is the number of digrams appearing once and
is the number of digrams appearing once and 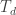 is the total number of digrams, they use a “di-gram repetition factor”
is the total number of digrams, they use a “di-gram repetition factor”
 is chosen via cross-validation on known corpora.
is chosen via cross-validation on known corpora. to a threshold — if it is small then they deem the system to be more “heraldic”. If
to a threshold — if it is small then they deem the system to be more “heraldic”. If  . If
. If 