Well, if not decipher, at least claim that there is something to read. A recent paper claims that Pictish inscriptions are a form of written language:
Lo and behold, the Shannon entropy of Pictish inscriptions turned out to be what one would expect from a written language, and not from other symbolic representations such as heraldry.
The full paper has more details. From reading the popular account I thought it was just a simple hypothesis test using the empirical entropy as a test statistic and “heraldry” as the null hypothesis, but it is a little more complicated than that.
After identifying the set of symbols in Pictish inscriptions, the question is how related adjacent symbols are to each other. That is, can the symbols be read sequentially? What they do is renormalize Shannon’s 

where 

Another feature which the authors think is important is the number of digrams which are repeated in the text. If 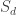
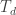

where the tradeoff factor 
They then propose a two-step decision process. First they compare 

In this paper “entropy” is being used here as some statistic with discriminatory value. It is not clear a priori that human writing systems should display empirical entropies with certain values, but since it works well on other known corpora, it seems like reasonable evidence. I think the authors are relatively careful about this, which is nice, since popular news might make one think that purported alien transmissions could easily fall to a similar analysis. Maybe that’s how Jeff Goldblum mnanaged to get his Mac to reprogram the alien ship in Independence Day…
Update: I forgot to link to a few related things. The statistics in this paper are a little more convincing than the work on the Indus script (see Cosma’s lengthy analysis. In particular, they do a little better job of justifying their statistic as discriminating in known corpora. Pictish would seem to be woefully undersampled, so it is important to justify the statistic as discriminatory for small data sets.

Pingback: Shannon Entropy Deciphers Pictish « Big Numbers