The Wizard of The Crow [N’gugi wa Thiong’o] — This is an epic political farce about an African dictatorship. It’s a bit slow getting into it, but once I was about 70 pages in I was hooked. It’s absolutely hilarious and tragic at the same time. I’ve not read a book like this in a while. Ngugi’s imagination is broad and open, so the absurd situations just keep escalating and mutating. One of the effects is that if you looked at the situation midway through the book, you would ordinarily have no idea how things came to such a state, but thanks to the storytelling you can see the absurd (yet stepwise somewhat reasonable) sequence of events that led there. From now on I will always have the phrase “queueing mania” in my head. Highly recommended.
Proofs and Refutations [Imre Lakatos] — “Why did I not read this book years ago?” I asked myself about a third of the way through this book. Lakatos breaks down the process of mathematical reasoning by example, showing how arguments (and statements) are refined through an alternating process of proof-strategies and counterexamples. It’s a bit of a dry read but it made me more excited about trying to take on some new and meatier theoretical problems. It also made me want to read some Feyerabend, which I am doing now…
The Crown of Embers [Rae Carson] — a continuation of Carson’s YA series set in a sort of pseudo Spanish colonialist fantasy land. It’s hard to parse out the politics of it, but I’m willing to see where the series goes before deciding if it is really subverts the typical racial essentialization that’s typical of fantasy. The colonial aspect of it makes it most problematic.
The Wee Free Men [Terry Pratchett] — a YA Discworld novel. Feels fresher than the other later Pratchett Discworld books.
Equal Rites [Terry Pratchett] — an early Discworld novel. Feels a little thinner than some of the others, but it had some cute moments.
The Republic of Wine [Mo Yan] — Another political farce, this time set in China. This has to be one of the more grotesque and crass novels I have read… maybe ever. The title might be better translated (and Americanized) as “Boozelandia.” The novel is part correspondence between an author (named Mo Yan) and an aspiring writer from the state of “Liquorland,” partly short stories by said aspiring writer, and partly a story about an investigator sent to ascertain whether state officials are raising children to be eaten at fancy dinners. It’s got a kind of gonzo style that will definitely appeal to some. I liked it in the end but I was also totally unaware of what I was getting into when I opened it.
such that the following holds. Let
be an
real matrix such that the
-th column
satisfies
for
, and let
be a convex body in
such that
, where
. Then there exists a vector
such that
.
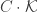


 pairs of cards. The cards in each pair are identical. The deck is shuffled and the cards laid face down. A move consists of flipping over first one card and then another. The cards are removed from play if they match. Otherwise, they are flipped back over and the next move commences. A game ends when all pairs have been matched. We determine that, when the game is played optimally, as
pairs of cards. The cards in each pair are identical. The deck is shuffled and the cards laid face down. A move consists of flipping over first one card and then another. The cards are removed from play if they match. Otherwise, they are flipped back over and the next move commences. A game ends when all pairs have been matched. We determine that, when the game is played optimally, as 
 .
.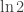 .
. .
.
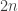 moves by flipping every card over once (there are
moves by flipping every card over once (there are  cards) to learn all of their identities and then removing all of the pairs one by one. The better strategy is
cards) to learn all of their identities and then removing all of the pairs one by one. The better strategy is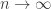 , I wonder if there is a more “probabilistic” argument (this is perhaps a bit fuzzy) for the results.
, I wonder if there is a more “probabilistic” argument (this is perhaps a bit fuzzy) for the results.
 balls and
balls and 