Verrrrrry belated blogging on the rest of the workshop, more than a month later. Day 2 had 5 talks instead of the tutorial plus talks, and the topics were a bit more varied (this was partly because of scheduling issues that prevented us from being strictly thematic).
Amos Beimel started out with a talk on secret sharing, which had a very nice tutorial/introduction to the problem, including the connection between Reed-Solomon codes and Shamir’s t-out-of-n scheme. For professional (and perhaps personal) reasons I found myself wondering how much more the connection between secret sharing and coding theory was — after all, this was a workshop about communication between information theory and theoretical CS. Not being a coding theory expert myself, I could only speculate. What I didn’t know about was the more general secret sharing structures and the results of Ito-Saito-Nishizeki scheme (published in Globecom!). Amos also talked about monotone span programs, which were new to me, and how to prove lower bounds. He concluded with more recent work on the related distribution design problem: how can we construct a distribution on n variables given constraints that specify subsets which should have identical marginals and subsets which should have disjoint support? The results appeared in ICTS.
Ye Wang talked about his work on common information and how it appears in privacy and security problems from an information theoretic perspective. In particular he talked about secure sampling, multiparty computation, and data release problems. The MPC and sampling results were pretty technical in terms of notions of completeness of primitives (conditional distributions) and triviality (a way of categorizing sources). For the data release problem he focused on problems where a sanitizer has access to a pair  where
where  is private and
is private and  is “useful” — the goal is to produce a version of the data which reveals less about (privacy) and more about (utility). Since they are correlated, there is a tension. The question he addressed is when having access to Y alone as as good as both X and Y.
is “useful” — the goal is to produce a version of the data which reveals less about (privacy) and more about (utility). Since they are correlated, there is a tension. The question he addressed is when having access to Y alone as as good as both X and Y.
Manoj, after giving his part of the tutorial (and covering for Vinod), gave his own talk on what he called “cryptographic complexity,” which is an analogy to computational complexity, but for multiparty functions. This was also a talk about definitions and reductions: if you can build a protocol for securely computing 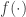 using a protocol for
using a protocol for 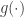 , then reduces to . A complete function is one for which everything reduces to it, and a trivial function reduces to everything. So with the concepts you can start to classify and partition out functions like characterizing all complete functions for 2 parties, or finding trivial functions under different security notions. He presented some weird facts, like an
, then reduces to . A complete function is one for which everything reduces to it, and a trivial function reduces to everything. So with the concepts you can start to classify and partition out functions like characterizing all complete functions for 2 parties, or finding trivial functions under different security notions. He presented some weird facts, like an  bit XOR doesn’t reduce to an
bit XOR doesn’t reduce to an 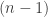 bit XOR. It was a pretty interesting talk, and I learned quite a bit!
bit XOR. It was a pretty interesting talk, and I learned quite a bit!
Elette Boyle gave a great talk on Oblivious RAM, a topic about which I was completely oblivious myself. The basic idea in oblivious RAM is (as I understood it) that an adversary can observe the accesses to a RAM and therefore infer what program is being executed (and the input). To obfuscate that, you introduce a bunch of spurious accesses. So if you have a program $\latex \Pi$ whose access pattern is fixed prior to execution, you can randomize the accesses and gain some security. The overhead is the ratio of the total accesses to the required accesses. After this introduction to the problem, she talked about lower bounds on the overhead (e.g. you need this much overhead) for a case where you have parallel processing. I admit that I didn’t quite understand the arguments, but the problem was pretty interesting.
Hoeteck Wee gave the last (but quite energetic) talk of the afternoon, on what he called “functional encryption.” The ideas is that Alice has 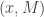 and Bob has
and Bob has  . They both send messages to a third party, Charlie. There is a 0-1 function (predicate)
. They both send messages to a third party, Charlie. There is a 0-1 function (predicate)  such that if
such that if  then Charlie can decode the message
then Charlie can decode the message  . Otherwise, they cannot. An example would be the predicate
. Otherwise, they cannot. An example would be the predicate  . In this case, Alice can send
. In this case, Alice can send 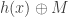 and Bob can send
and Bob can send  for some 2-wise independent hash function, and then Charlie can recover if the hashes match. I think there is a question in this scheme about whether Charlie needs to know that they got the right message, but I guess I can read the paper for that. The kinds of questions they want to ask are what kinds of predicates have nice encoding schemes? What is the size of message that Alice and Bob have to send? He made a connection/reduction to a communication complexity problem to get a bound on the message sizes in terms of the communication complexity of computing the predicate
for some 2-wise independent hash function, and then Charlie can recover if the hashes match. I think there is a question in this scheme about whether Charlie needs to know that they got the right message, but I guess I can read the paper for that. The kinds of questions they want to ask are what kinds of predicates have nice encoding schemes? What is the size of message that Alice and Bob have to send? He made a connection/reduction to a communication complexity problem to get a bound on the message sizes in terms of the communication complexity of computing the predicate  . It really was a very nice talk and pretty understandable even with my own limited background.
. It really was a very nice talk and pretty understandable even with my own limited background.

