The advantage of flying to Hong Kong from the US is that the jet lag was such that I was actually more or less awake in the mornings. I didn’t take such great notes during the plenaries, but they were rather enjoyable, and I hope that the video will be uploaded to the ITSOC website soon.
There were several talks on entropy estimation in various settings that I did not take great notes on, to wit:
- OPTIMAL ENTROPY ESTIMATION ON LARGE ALPHABETS VIA BEST POLYNOMIAL APPROXIMATION (Yihong Wu, Pengkun Yang, University Of Illinois, United States)
- DOES DIRICHLET PRIOR SMOOTHING SOLVE THE SHANNON ENTROPY ESTIMATION PROBLEM? (Yanjun Han, Tsinghua University, China; Jiantao Jiao, Tsachy Weissman, Stanford University, United States)
- ADAPTIVE ESTIMATION OF SHANNON ENTROPY (Yanjun Han, Tsinghua University, China; Jiantao Jiao, Tsachy Weissman, Stanford University, United States)
I would highly recommend taking a look for those who are interested in this problem. In particular, it looks like we’re getting towards more efficient entropy estimators in difficult settings (online, large alphabet), which is pretty exciting.
QUICKEST LINEAR SEARCH OVER CORRELATED SEQUENCES
Javad Heydari, Ali Tajer, Rensselaer Polytechnic Institute, United States
This talk was about hypothesis testing where the observer can control the samples being taken by traversing a graph. We have an  -node graph (c.f. a graphical model) representing the joint distribution on variables. The data generated is i.i.d. across time according to either
-node graph (c.f. a graphical model) representing the joint distribution on variables. The data generated is i.i.d. across time according to either  or
or 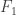 . At each time you get to observe the data from only one node of the graph. You can either observe the same node as before, explore by observing a different node, or make a decision about whether the data from from or . By adopting some costs for different actions you can form a dynamic programming solution for the search strategy but it’s pretty heavy computationally. It turns out the optimal rule for switching has a two-threshold structure and can be quite a bit different than independent observations when the correlations are structured appropriately.
. At each time you get to observe the data from only one node of the graph. You can either observe the same node as before, explore by observing a different node, or make a decision about whether the data from from or . By adopting some costs for different actions you can form a dynamic programming solution for the search strategy but it’s pretty heavy computationally. It turns out the optimal rule for switching has a two-threshold structure and can be quite a bit different than independent observations when the correlations are structured appropriately.
MISMATCHED ESTIMATION IN LARGE LINEAR SYSTEMS
Yanting Ma, Dror Baron, North Carolina State University, United States; Ahmad Beirami, Duke University, United States
The mismatch studied in this paper is a mismatch in the prior distribution for a sparse observation problem  , where
, where  (say a Bernoulli-Gaussian prior). The question is what happens when we do estimation assuming a different prior
(say a Bernoulli-Gaussian prior). The question is what happens when we do estimation assuming a different prior  . The main result of the paper is an analysis of the excess MSE using a decoupling principle. Since I don’t really know anything about the replica method (except the name “replica method”), I had a little bit of a hard time following the talk as a non-expert, but thankfully there were a number of pictures and examples to help me follow along.
. The main result of the paper is an analysis of the excess MSE using a decoupling principle. Since I don’t really know anything about the replica method (except the name “replica method”), I had a little bit of a hard time following the talk as a non-expert, but thankfully there were a number of pictures and examples to help me follow along.
SEARCHING FOR MULTIPLE TARGETS WITH MEASUREMENT DEPENDENT NOISE
Yonatan Kaspi, University of California, San Diego, United States; Ofer Shayevitz, Tel-Aviv University, Israel; Tara Javidi, University of California, San Diego, United States
This was another search paper, but this time we have, say,  targets
targets  uniformly distributed in the unit interval, and what we can do is query at each time a set
uniformly distributed in the unit interval, and what we can do is query at each time a set ![S_n \subseteq [0,1]](https://s0.wp.com/latex.php?latex=S_n+%5Csubseteq+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and get a response
and get a response  where
where  and
and  where
where  is the Lebesgue measure. So basically you can query a set and you get a noisy indicator of whether you hit any targets, where the noise depends on the size of the set you query. At some point
is the Lebesgue measure. So basically you can query a set and you get a noisy indicator of whether you hit any targets, where the noise depends on the size of the set you query. At some point  you stop and guess the target locations. You are
you stop and guess the target locations. You are  successful if the probability that you are within
successful if the probability that you are within  of each target is less than
of each target is less than  . The targeting rate is the limit of
. The targeting rate is the limit of ![\log(1/\delta) / \mathbb{E}[\tau]](https://s0.wp.com/latex.php?latex=%5Clog%281%2F%5Cdelta%29+%2F+%5Cmathbb%7BE%7D%5B%5Ctau%5D&bg=ffffff&fg=333333&s=0&c=20201002) as
as  (I’m being fast and loose here). Clearly there are some connections to group testing and communication with feedback, etc. They show there is a significant gap between the adaptive and nonadaptive rate here, so you can find more targets if you can adapt your queries on the fly. However, since rate is defined for a fixed number of targets, we could ask how the gap varies with . They show it shrinks.
(I’m being fast and loose here). Clearly there are some connections to group testing and communication with feedback, etc. They show there is a significant gap between the adaptive and nonadaptive rate here, so you can find more targets if you can adapt your queries on the fly. However, since rate is defined for a fixed number of targets, we could ask how the gap varies with . They show it shrinks.
ON MODEL MISSPECIFICATION AND KL SEPARATION FOR GAUSSIAN GRAPHICAL MODELS
Varun Jog, University of California, Berkeley, United States; Po-Ling Loh, University of Pennsylvania, United States
The graphical model for jointly Gaussian variables has no edge between nodes  and
and  if the corresponding entry
if the corresponding entry 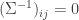 in the inverse covariance matrix. They show a relationship between the KL divergence of two distributions and their corresponding graphs. The divergence is lower bounded by a constant if they differ in a single edge — this indicates that estimating the edge structure is important when estimating the distribution.
in the inverse covariance matrix. They show a relationship between the KL divergence of two distributions and their corresponding graphs. The divergence is lower bounded by a constant if they differ in a single edge — this indicates that estimating the edge structure is important when estimating the distribution.
CONVERSES FOR DISTRIBUTED ESTIMATION VIA STRONG DATA PROCESSING INEQUALITIES
Aolin Xu, Maxim Raginsky, University of Illinois at Urbana–Champaign, United States
Max gave a nice talk on the problem of minimizing an expected loss ![\mathbb{E}[ \ell(W, \hat{W}) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Cell%28W%2C+%5Chat%7BW%7D%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002) of a
of a  -dimensional parameter
-dimensional parameter  which is observed noisily by separate encoders. Think of a CEO-style problem where there is a conditional distribution
which is observed noisily by separate encoders. Think of a CEO-style problem where there is a conditional distribution  such that the observation at each node is a
such that the observation at each node is a  matrix whose columns are i.i.d. and where the -th row is i.i.d. according to
matrix whose columns are i.i.d. and where the -th row is i.i.d. according to  . Each sensor gets independent observations from the same model and can compress its observations to
. Each sensor gets independent observations from the same model and can compress its observations to  bits and sends it over independent channels to an estimator (so no MAC here). The main result is a lower bound on the expected loss as s function of the number of bits latex , the mutual information between and the final estimate
bits and sends it over independent channels to an estimator (so no MAC here). The main result is a lower bound on the expected loss as s function of the number of bits latex , the mutual information between and the final estimate 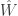 . The key is to use the strong data processing inequality to handle the mutual information — the constants that make up the ratio between the mutual informations is important. I’m sure Max will blog more about the result so I’ll leave a full explanation to him (see what I did there?)
. The key is to use the strong data processing inequality to handle the mutual information — the constants that make up the ratio between the mutual informations is important. I’m sure Max will blog more about the result so I’ll leave a full explanation to him (see what I did there?)
More on Shannon theory etc. later!



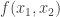







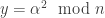


![\{ x_i : i \in [N] \}](https://s0.wp.com/latex.php?latex=%5C%7B+x_i+%3A+i+%5Cin+%5BN%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
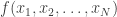
![\{y_i : i \in [N]\}](https://s0.wp.com/latex.php?latex=%5C%7By_i+%3A+i+%5Cin+%5BN%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
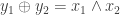



![x[n+1] = x[n] + B[n] u[n]](https://s0.wp.com/latex.php?latex=x%5Bn%2B1%5D+%3D+x%5Bn%5D+%2B+B%5Bn%5D+u%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where ![B[n]](https://s0.wp.com/latex.php?latex=B%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) has the uncertainty. She gave a couple of different notions of capacity, relating to the ratio
has the uncertainty. She gave a couple of different notions of capacity, relating to the ratio ![| x[n]/x[0] |](https://s0.wp.com/latex.php?latex=%7C+x%5Bn%5D%2Fx%5B0%5D+%7C&bg=ffffff&fg=333333&s=0&c=20201002) — either the expected value of the square or the log, appropriately normalized. She used a “deterministic model” to give an explanation of how control in this setting is kind of like controlling the number of significant bits in the state: uncertainty increases this and you need a certain “amount” of control to cancel that growth.
— either the expected value of the square or the log, appropriately normalized. She used a “deterministic model” to give an explanation of how control in this setting is kind of like controlling the number of significant bits in the state: uncertainty increases this and you need a certain “amount” of control to cancel that growth.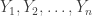 , the null hypothesis is that they are all i.i.d.
, the null hypothesis is that they are all i.i.d. 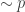 and the (composite) alternative is that there an interval of indices which are
and the (composite) alternative is that there an interval of indices which are  instead. She proposed a RKHS-based discrepancy measure and a threshold test on this measure. Pradeep Ravikumar talked about a “simple” estimator that was a “fix” for ordinary least squares with some soft thresholding. He showed consistency for linear regression in several senses, competitive with LASSO in some settings. Pretty neat, all said, although he also claimed that least squares was “something you all know from high school” — I went to a
instead. She proposed a RKHS-based discrepancy measure and a threshold test on this measure. Pradeep Ravikumar talked about a “simple” estimator that was a “fix” for ordinary least squares with some soft thresholding. He showed consistency for linear regression in several senses, competitive with LASSO in some settings. Pretty neat, all said, although he also claimed that least squares was “something you all know from high school” — I went to a 