Wrapping this up, finally. Maybe conference blogging has to go by the wayside for me… my notes got a bit sketchier so I’ll just do a short rundown of the topics.
Days 4-5 were a series of “short” talks by Moni Naor, Kobbi Nissim, Lalitha Sankar, Sewoong Oh, Delaram Kahrobaie, Joerg Kliewer, Jon Ullman, and Sasho Nikolov on a rather eclectic mix of topics.
Moni’s talk was on secret sharing in an online setting — parties arrive one by one and the qualified sets (who can decode the secret) is revealed by all parties. The shares have to be generated online as well. Since the access structure is evolving, what kinds of systems can we support? As I understood it, the idea is to use something similar to threshold scheme and a “doubling trick”-like argument by dividing the users/parties into generations. It’s a bit out of area for me so I had a hard time keeping up with the connections to other problems. Kobbi talked about reconstruction attacks based on observing traffic from outsourced database systems. A user wants to get the records but the server shouldn’t be able to reconstruct: it knows how many records were returned from a query and knows if the same record was sent on subsequent queries — this is a sort of access pattern leakage. He presented attacks based on this information and also based on just knowing the volume (e.g. total size of response) from the queries.
Lalitha talked about mutual information privacy, which was quite a bit different than the differential privacy models from the CS side, but more in line with Ye Wang’s talk earlier in the week. Although she didn’t get to spend as much time on it, the work on interactive communication and privacy might have been interesting to folks earlier in the workshop studying communication complexity. In general, the connection between communication complexity problems and MPC, for example, are elusive to me (probably from lack of trying).
Sewoong talked about optimal mechanisms for differentially private composition — I had to miss his talk, unfortunately. Delaram talked about cryptosystems based on group theory and I had to try and check back in all the things I learned in 18.701/702 and the graduate algebra class I (mistakenly) took my first year of graduate school. I am not sure I could even do justice to it, but I took a lot of notes. Joerg talked about using polar codes to enable private function computation — initially privacy was measured by equivocation but towards the end he made a connection to differential privacy. Since most folks (myself included) are not experts on polar codes, he gave a rather nice tutorial (I thought) on polar coding. It being the last day of the workshop, the audience had unfortunately thinned out a bit.
Jon spoke about estimating marginal distributions for high-dimensional problems. There were some nice connections to composite hypothesis testing problems that came out of the discussion during the talk — the model seems a bit complex to get into based on my notes, but I think readers who are experts on hypothesis testing might want to check out his work. Sasho rounded off the workshop with a talk about the sensitivity polytope of linear queries on a statistical database and connections to Gaussian widths. The main result was on the sample complexity of answering the queries in time polynomial in the number of individuals, size of the universe, and size of the query set.

 parties with inputs
parties with inputs 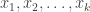 want to exchange messages to implement a functionality (evaluate a function)
want to exchange messages to implement a functionality (evaluate a function)  over secure point-to-point channels such they successfully learn the output of the function but don’t learn anything additional about each others’ inputs. There is a landscape of definitions within this general framework: some parties could collude, behave dishonestly with respect to the protocol, and so on. The guarantees could be exact (in the real/ideal paradigm in which you compare the real system with an simulated system), statistical (the distribution in the real system is close in total variation distance to an ideal evaluation), or computational (some notion of indistinguishability). The example became a bit clearer when he described a 2-party example with a “trusted dealer” who can give parties some correlated random bits and they could use those to randomly shift the truth table/evaluation of
over secure point-to-point channels such they successfully learn the output of the function but don’t learn anything additional about each others’ inputs. There is a landscape of definitions within this general framework: some parties could collude, behave dishonestly with respect to the protocol, and so on. The guarantees could be exact (in the real/ideal paradigm in which you compare the real system with an simulated system), statistical (the distribution in the real system is close in total variation distance to an ideal evaluation), or computational (some notion of indistinguishability). The example became a bit clearer when he described a 2-party example with a “trusted dealer” who can give parties some correlated random bits and they could use those to randomly shift the truth table/evaluation of 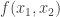 to guarantee correctness and security.
to guarantee correctness and security. , can you simulate/compute
, can you simulate/compute  using calls to
using calls to  is true and can ask queries to a prover
is true and can ask queries to a prover  which has some evidence
which has some evidence  that it wants to keep secret. For example, the statement might be “the number
that it wants to keep secret. For example, the statement might be “the number  is a perfect square” and the evidence might be an
is a perfect square” and the evidence might be an  such that
such that 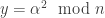 . The prover doesn’t want to reveal
. The prover doesn’t want to reveal  , but instead should convince the verifier that such an
, but instead should convince the verifier that such an 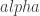 exists. She gave a protocol for this before turning to a more complicated statement like proving that a graph has a Hamiltonian cycle. She then talked about using commitment schemes, at which point I sort of lost the thread of things since I’m not as familiar with these cryptography constructions. I probably should have asked more questions, so it was my loss.
exists. She gave a protocol for this before turning to a more complicated statement like proving that a graph has a Hamiltonian cycle. She then talked about using commitment schemes, at which point I sort of lost the thread of things since I’m not as familiar with these cryptography constructions. I probably should have asked more questions, so it was my loss. users who encrypt values
users who encrypt values ![\{ x_i : i \in [N] \}](https://s0.wp.com/latex.php?latex=%5C%7B+x_i+%3A+i+%5Cin+%5BN%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) with their public key and upload them to a server. Someone with access to the server wants to be able to decode only a function
with their public key and upload them to a server. Someone with access to the server wants to be able to decode only a function 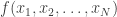 using the combined private keys of all the users. In “spooky” FHE, you have
using the combined private keys of all the users. In “spooky” FHE, you have ![\{y_i : i \in [N]\}](https://s0.wp.com/latex.php?latex=%5C%7By_i+%3A+i+%5Cin+%5BN%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) which are functions of all of the encoded data. A simple example of this is when
which are functions of all of the encoded data. A simple example of this is when 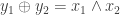 : that is, the XOR of the outputs is equal to the AND of the inputs. This generalizes to the XOR of multiple outputs being some function of the inputs, something he called additive function sharing. He then presented schemes for these two problems based on the
: that is, the XOR of the outputs is equal to the AND of the inputs. This generalizes to the XOR of multiple outputs being some function of the inputs, something he called additive function sharing. He then presented schemes for these two problems based on the  . Perhaps there are some connections to linear block codes or network coding to be exploited here.
. Perhaps there are some connections to linear block codes or network coding to be exploited here.