
The view from my office at IHP
I am attending the Nexus of Information and Computation Theories workshop at the Institut Henri Poincaré in Paris this week. It’s the last week of a 10 week program that brought together researchers from information theory and CS theory in workshops around various themes such as distributed computation, inference, lower bounds, inequalities, and security/privacy. The main organizers were Bobak Nazer, Aslan Tchamkerten, Anup Rao, and Mark Braverman. The last two weeks are on Privacy and Security: I helped organize these two weeks with Prakash Narayan, Salil Vadhan, Aaron Roth, and Vinod Vaikuntanathan.
Due to teaching and ICASSP, I missed last week, but am here for this week, for which the sub-topics are security multiparty computation and differential privacy. I’ll try to blog about the workshop since I failed to blog at all about ITA, CISS, or ICASSP. The structure of the workshop was to have 4 tutorials (two per week) and then a set of hopefully related talks. The first week had tutorials on pseudorandomness and information theoretic secrecy.
The second week of the workshop kicked off with a tutorial from Yuval Ishai and Manoj Prabhakaran on secure multiparty computation (MPC). Yuval gave an abbreviated version/update of his tutorial from the Simons Institute (pt1/pt2) that set up the basic framework and language around MPC:  parties with inputs
parties with inputs 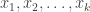 want to exchange messages to implement a functionality (evaluate a function)
want to exchange messages to implement a functionality (evaluate a function)  over secure point-to-point channels such they successfully learn the output of the function but don’t learn anything additional about each others’ inputs. There is a landscape of definitions within this general framework: some parties could collude, behave dishonestly with respect to the protocol, and so on. The guarantees could be exact (in the real/ideal paradigm in which you compare the real system with an simulated system), statistical (the distribution in the real system is close in total variation distance to an ideal evaluation), or computational (some notion of indistinguishability). The example became a bit clearer when he described a 2-party example with a “trusted dealer” who can give parties some correlated random bits and they could use those to randomly shift the truth table/evaluation of
over secure point-to-point channels such they successfully learn the output of the function but don’t learn anything additional about each others’ inputs. There is a landscape of definitions within this general framework: some parties could collude, behave dishonestly with respect to the protocol, and so on. The guarantees could be exact (in the real/ideal paradigm in which you compare the real system with an simulated system), statistical (the distribution in the real system is close in total variation distance to an ideal evaluation), or computational (some notion of indistinguishability). The example became a bit clearer when he described a 2-party example with a “trusted dealer” who can give parties some correlated random bits and they could use those to randomly shift the truth table/evaluation of 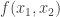 to guarantee correctness and security.
to guarantee correctness and security.
Manoj, on the other hand talked about some notions of reductions between secure computations: given a protocol which evaluates  , can you simulate/compute
, can you simulate/compute  using calls to ? How many do you need? this gives a notion of the complexity rate of one function in terms of another. For example, can Alice and Bob simulate a BEC using calls to an oblivious transfer (OT) protocol? What about vice versa? What about using a BSC? These problems seem sort of like toy channel problems (from an information theory perspective) but seem like fundamental building blocks when thinking about secure computation. As I discussed with Hoeteck Wee today, in information theory we often gain some intuition from continuous alphabets or large/general alphabet settings, whereas cryptography arguments/bounds come from considering circuit complexity: these are ideas that we don’t think about too much in IT since we don’t usually care about computational complexity/implementation.
using calls to ? How many do you need? this gives a notion of the complexity rate of one function in terms of another. For example, can Alice and Bob simulate a BEC using calls to an oblivious transfer (OT) protocol? What about vice versa? What about using a BSC? These problems seem sort of like toy channel problems (from an information theory perspective) but seem like fundamental building blocks when thinking about secure computation. As I discussed with Hoeteck Wee today, in information theory we often gain some intuition from continuous alphabets or large/general alphabet settings, whereas cryptography arguments/bounds come from considering circuit complexity: these are ideas that we don’t think about too much in IT since we don’t usually care about computational complexity/implementation.
Huijia (Rachel) Lin gave an introduction to zero-knowledge proofs and proof systems: a verifier wants to know if a statement  is true and can ask queries to a prover
is true and can ask queries to a prover  which has some evidence
which has some evidence  that it wants to keep secret. For example, the statement might be “the number
that it wants to keep secret. For example, the statement might be “the number  is a perfect square” and the evidence might be an
is a perfect square” and the evidence might be an  such that
such that 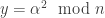 . The prover doesn’t want to reveal
. The prover doesn’t want to reveal  , but instead should convince the verifier that such an
, but instead should convince the verifier that such an 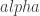 exists. She gave a protocol for this before turning to a more complicated statement like proving that a graph has a Hamiltonian cycle. She then talked about using commitment schemes, at which point I sort of lost the thread of things since I’m not as familiar with these cryptography constructions. I probably should have asked more questions, so it was my loss.
exists. She gave a protocol for this before turning to a more complicated statement like proving that a graph has a Hamiltonian cycle. She then talked about using commitment schemes, at which point I sort of lost the thread of things since I’m not as familiar with these cryptography constructions. I probably should have asked more questions, so it was my loss.
Daniel Wichs discussed two problems he called “multi-key” and “spooky” fully-homomorphic encryption (FHE). The idea in multi-key FHE is that you have  users who encrypt values
users who encrypt values ![\{ x_i : i \in [N] \}](https://s0.wp.com/latex.php?latex=%5C%7B+x_i+%3A+i+%5Cin+%5BN%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) with their public key and upload them to a server. Someone with access to the server wants to be able to decode only a function
with their public key and upload them to a server. Someone with access to the server wants to be able to decode only a function 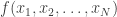 using the combined private keys of all the users. In “spooky” FHE, you have decoders, each with one of the private keys, but they want to decode values
using the combined private keys of all the users. In “spooky” FHE, you have decoders, each with one of the private keys, but they want to decode values ![\{y_i : i \in [N]\}](https://s0.wp.com/latex.php?latex=%5C%7By_i+%3A+i+%5Cin+%5BN%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) which are functions of all of the encoded data. A simple example of this is when
which are functions of all of the encoded data. A simple example of this is when 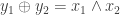 : that is, the XOR of the outputs is equal to the AND of the inputs. This generalizes to the XOR of multiple outputs being some function of the inputs, something he called additive function sharing. He then presented schemes for these two problems based on the “learning with errors” from Gentry, Sahai, and Waters, which I would apparently have to read to really understand the scheme. It’s some sort of linear algebra thing over
: that is, the XOR of the outputs is equal to the AND of the inputs. This generalizes to the XOR of multiple outputs being some function of the inputs, something he called additive function sharing. He then presented schemes for these two problems based on the “learning with errors” from Gentry, Sahai, and Waters, which I would apparently have to read to really understand the scheme. It’s some sort of linear algebra thing over  . Perhaps there are some connections to linear block codes or network coding to be exploited here.
. Perhaps there are some connections to linear block codes or network coding to be exploited here.
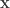 and each test is the row or a matrix
and each test is the row or a matrix  : the
: the  -the entry of
-the entry of  -th item is part of the
-th item is part of the  -th group. The multiplication
-th group. The multiplication  is taken using Boolean OR. The twist in this paper is that they consider a situation where
is taken using Boolean OR. The twist in this paper is that they consider a situation where  elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like
elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like  . They show achievable rates for detecting the positives using random coding methods (i.e. a random
. They show achievable rates for detecting the positives using random coding methods (i.e. a random 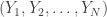 from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this:
from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this: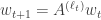 for
for 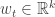 with
with 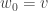

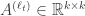 as the transition for state
as the transition for state  (e.g. a stochastic matrix) and we want the output to be
(e.g. a stochastic matrix) and we want the output to be 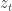 . This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if
. This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if 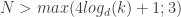 , where
, where  is the size of the output alphabet size, and
is the size of the output alphabet size, and 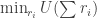
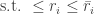

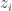 are private but the charging rates
are private but the charging rates  can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps.
can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps. for computing a function
for computing a function  interactively, where Alice has
interactively, where Alice has  , and
, and  :
:
 -tuples of variables
-tuples of variables  -accurately approaches the minimum information complexity over all protocols for computing
-accurately approaches the minimum information complexity over all protocols for computing  during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra
during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra  in dimension
in dimension  and the sphere
and the sphere  of radius
of radius  around
around  vectors
vectors  uniformly from the surface of the unit sphere, and consider the polytope defined by faces which are tangent to
uniformly from the surface of the unit sphere, and consider the polytope defined by faces which are tangent to  for
for  . That is, the vector
. That is, the vector  . The goal is to find how
. The goal is to find how 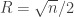 , then we will always have an integer point. What should the real scaling for
, then we will always have an integer point. What should the real scaling for  and
and 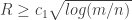 , with high probability the polytope will have an integer point for every
, with high probability the polytope will have an integer point for every 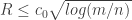 , then with high probability the polytope “centered” at
, then with high probability the polytope “centered” at  with not contain an integer point. Note that if the number of faces is linear in
with not contain an integer point. Note that if the number of faces is linear in  geometry gives better intuition.
geometry gives better intuition.