I’m at CISS right now on the magnolia-filled Princeton campus. The last time I came here was in 2008, when I was trying to graduate and was horribly ill, so this year was already a marked improvement. CISS bears some similarities to Allerton — there are several invited sessions in which the talks are a little longer than the submitted sessions. However, the session organizers get to schedule the entire morning or afternoon (3 hours) as they see fit, so hopping between sessions is not usually possible. I actually find this more relaxing — I know where I’m going to be for the afternoon, so I just settle down there instead of watching the clock so I don’t miss talk X in the other session.
Because there are these invited slots, I’ve begun to realize that I’ve seen some of the material before in other venues such as ITA. This is actually a good thing — in general, I’ve begun to realized that I have to see things 3 times for me to wrap my brain around them.
In the morning I went to Wojciech Szpankowski‘s session on the Science of Information, a sort of showcase for the new multi-university NSF Center. Peter Shor gave an overview of quantum information theory, ending with comments on the additivity conjecture. William Bialek discussed how improvements in array sensors for multi-neuron recording and other measurement technologies are allowing experimental verification of some theoretical/statistical approaches to neuroscience and communication in biological systems. In particular, he discussed an interesting example of how segmentation appears in the embryonic development of fruit flies and how they can track the propagation of chemical markers during development.
David Tse gave a slightly longer version of his ITA talk (with on DNA sequencing with more of the proof details. It’s a cute version of the genome assembly problem but I am not entirely sure what it tells us about the host of other questions biologists have about this data. I’m trying to wrestle with some short-read sequencing data to understand it (and learning some Bioconductor in the process), and the real data is pretty darn messy.
Madhu Sudan talked about his work with Brendan Juba (and now Oded Goldreich) on Semantic Communication — it’s mostly trying to come up with definitions of what it means to communicate meaning using computer science, and somehow feels like some of these early papers in Information and Control which tried to mathematize linguistics or other fields. This is the magical 3rd time I’ve seen this material, so maybe it’s starting to make sense to me.
Andrea Goldsmith gave a whirlwind tour of the work in backing away from asymptotic studies in information theory, and how insights we get from asymptotic analyses often don’t translate into the finite parameter regime. This is of a piece with her stand a few years ago on cross-layer design. High SNR assumptions in MIMO and relaying imply that certain tradeoffs (such diversity-multiplexing) or certain protocols (such as amplify-and forward) are fundamental but at moderate SNR the optimal strategies are different or unknown. Infinite blocklengths are the bread and butter of information theory but now there are more results on what we can do with finite blocklength. She ended with some comments on infinite processing power and trying to consider transmit and processing power jointly, which caused some debate in the audience.
Alas, I missed Tsachy Weissmann‘s talk, but at least I saw it at ITA? Perhaps I will get to see it two more times in the future!
In the afternoon I went to the large alphabets session which was organized by Aaron Wagner. Unfortunately, Aaron couldn’t make it so I ended up chairing the session. Venkat Chandrasekaran didn’t really talk about large alphabets, but instead about estimating high dimensional covariance matrices when you have symmetry assumptions on the matrix. These are represented by the invariance of the true covariance under actions of a subgroup of the symmetric group — taking these into account can greatly improve sample complexity bounds. Mesrob Ohanessian talked about his canonical estimation framework for large alphabet problems and summarized a lot of other work before (too briefly!) mentioning his own work on the consistency of estimators under some assumptions on the generating distribution.
Prasad Santhanam talked about the insurance problem that he worked on with Venkat Anantharam, and I finally understood it a bit better. Suppose you are observing i.i.d. samples 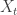 from a distribution
from a distribution  on
on  that represent losses paid out by an insurer. The insurer gets to observe the losses for a while and then has to start setting premiums
that represent losses paid out by an insurer. The insurer gets to observe the losses for a while and then has to start setting premiums 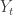 . The question is this : when can we guarantee that remains bounded and
. The question is this : when can we guarantee that remains bounded and  ? In this case we would say the distribution is insurable.
? In this case we would say the distribution is insurable.
To round out the session, Wojciech Szpankowski gave a talk on analytic approaches to bounding minimax redundancy under different scaling assumptions on the alphabet and sample sizes. There was a fair bit of generatingfunctionology and Lambert W-functions. The end part of the talk was on scaling when you know part of the distribution exactly (perhaps through offline simulation or training) but then there is part which is unknown. The last talk was by Greg Valiant, who talked about his papers with Paul Valiant on estimating properties of distributions on  elements using only
elements using only  samples. It was a variant of the talk he gave at Banff, but I think I understood the lower bound CLT results a bit better (using Stein’s Method).
samples. It was a variant of the talk he gave at Banff, but I think I understood the lower bound CLT results a bit better (using Stein’s Method).
I am not sure how much blogging I will do about the rest of the conference, but probably another post or two. Despite the drizzle, the spring is rather beautiful here — la joie du printemps.
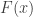 (with a density) on the unit interval
(with a density) on the unit interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . We can think of
. We can think of  as a level of approval (say of a politician) and
as a level of approval (say of a politician) and  i.i.d. from
i.i.d. from  and asks them to report their opinion. They can report anything they like, however, so they will report
and asks them to report their opinion. They can report anything they like, however, so they will report  . In order to incentivize them, the surveyor will issue a payment
. In order to incentivize them, the surveyor will issue a payment 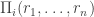 to each agent
to each agent  . How should we structure the payments to incentivize truthful reporting? In particular, can we make a mechanism in which being truthful is a Nash equilibrium (“accurate”) or the only Nash equilibrium (“strongly accurate”)?
. How should we structure the payments to incentivize truthful reporting? In particular, can we make a mechanism in which being truthful is a Nash equilibrium (“accurate”) or the only Nash equilibrium (“strongly accurate”)? . They propose partitioning the agents into
. They propose partitioning the agents into  groups with
groups with 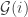 denoting the group of agent $i$, and
denoting the group of agent $i$, and 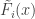 as an unbiased estimator of
as an unbiased estimator of  . The payments are:
. The payments are:![\Pi_i(\{r_j\}) = \frac{1}{|\mathcal{G}_i| - 1} \left[ A_i - B_i \right] + 2 \tilde{F}_i(r_i) - \frac{2}{|\mathcal{G}_i| - 1} \sum_{j \in \mathcal{G}_i \setminus \{i\} } \tilde{F}_j(r_j)](https://s0.wp.com/latex.php?latex=%5CPi_i%28%5C%7Br_j%5C%7D%29+%3D+%5Cfrac%7B1%7D%7B%7C%5Cmathcal%7BG%7D_i%7C+-+1%7D+%5Cleft%5B+A_i+-+B_i+%5Cright%5D+%2B+2+%5Ctilde%7BF%7D_i%28r_i%29+-+%5Cfrac%7B2%7D%7B%7C%5Cmathcal%7BG%7D_i%7C+-+1%7D+%5Csum_%7Bj+%5Cin+%5Cmathcal%7BG%7D_i+%5Csetminus+%5C%7Bi%5C%7D+%7D+%5Ctilde%7BF%7D_j%28r_j%29&bg=ffffff&fg=333333&s=0&c=20201002)
 and you want to get their sample of that distribution. Here what they do is replace the known distributions with empirical estimates, in a sense. Why is this only accurate and not strongly accurate? It is possible that the agents could collude and pick a different common distribution
and you want to get their sample of that distribution. Here what they do is replace the known distributions with empirical estimates, in a sense. Why is this only accurate and not strongly accurate? It is possible that the agents could collude and pick a different common distribution  and report values from that. Essentially, each group has an incentive to report from the same distribution and then globally the optimal thing is for all the groups to report from the same distribution, but that distribution need not be
and report values from that. Essentially, each group has an incentive to report from the same distribution and then globally the optimal thing is for all the groups to report from the same distribution, but that distribution need not be 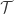 , then the estimators in the payment model can be built using the trusted data and the remaining untrusted agents can be put in a single group whose optimal strategy is now to follow the trusted agents. That mechanism is strongly accurate. In a sense the trusted agents cause the population to “gel” under this payment strategy.
, then the estimators in the payment model can be built using the trusted data and the remaining untrusted agents can be put in a single group whose optimal strategy is now to follow the trusted agents. That mechanism is strongly accurate. In a sense the trusted agents cause the population to “gel” under this payment strategy.