Almost a month later, I’m finishing up blogging about NIPS. Merry Christmas and all that (is anyone reading this thing?), and here’s to a productive 2013, research-wise. It’s a bit harder to blog these things because unlike a talk, it’s hard to take notes during a poster presentation.
Overall, I found NIPS to be a bit overwhelming — the single-track format makes it feel somehow more crowded than ISIT, but also it was hard for me to figure out how to strike the right balance of going to talks/posters and spending time talking to people and getting to know what they are working on. Now that I am fairly separated from my collaborators, conferences should be a good time to sit down and work on some problems, but somehow things are always a bit more frantic than I want them to be.
Anyway, from the rest of the conference, here are a few talks/posters that I went to and remembered something about.
T. Dietterich
Challenges for Machine Learning in Computational Sustainability
This was a plenary talk on machine learning problems that arise in natural resources management. There was a lot in this talk, and a lot of different problems ranging from prediction (for bird migrations, etc), imputation of missing data, and classification. These were real-world hands-on problems and one thing I got out of it is how much work you need to put into the making algorithms that work for the dat you have, rather than pulling some off-the-shelf works-great-in-theory method. He gave a version of this talk at TTI but I think the new version is better.
K. Muandet, K. Fukumizu, F. Dinuzzo, B. Schölkopf
Learning from Distributions via Support Measure Machines
This was on generalizing SVMs to take distributions as inputs instead of points — instead of getting individual points as training data, you get distributions (perhaps like clusters) and you have to do learning/classification on that kind of data. Part of the trick here is finding the right mathematical framework that remains computationally tractable.
J. Duchi, M. Jordan, M. Wainwright
Privacy Aware Learning
Since I work on privacy, this was of course interesting to me — John told me a bit about the work at Allerton. The model of privacy is different than the “standard” differential privacy model — data is stochastic and the algorithm itself (the learner) is not trusted, so noise has to be added to individual data points. A bird’s eye view of the idea is this : (1) stochastic gradient descent (SGD) is good for learning, and is robust to noise (e.g. noisy gradients), (2) noise is good at protecting privacy, so (3) SGD can be used to guarantee privacy by using noisy gradients. Privacy is measured here in terms of the mutual information between the data point and a noisy gradient using that data point. The result is a slowdown in the convergence rate that is a function of the mutual information bound, and it appears in the same place in the upper and lower bounds.
J. Wiens, J. Guttag, E. Horvitz
Patient Risk Stratification for Hospital-Associated C. Diff as a Time-Series Classification Task
This was a cool paper on predicting which patients would be infected with C. Diff (a common disease people get as a secondary infection from being the hospital). Since we have different data for each patient and lots of missing data, the classification problem is not easy — they try to assess a time-evolving risk of infection and then predict whether or not the patient will test positive for C. Diff.
P. Loh, M. Wainwright
No voodoo here! Learning discrete graphical models via inverse covariance estimation
This paper won a best paper award. The idea is that for Gaussian graphical models the inverse covariance matrix is graph-compatible — zeros correspond to missing edges. However, this is not true/easy to do for discrete graphical models. So instead they build the covariance matrix for all tuples of variables —  (really what they want is a triangulation of the graph) and then show that indeed, the inverse covariance matrix does respect the graph structure in a sense. More carefully, they have to augment the variables with the power set of the maximal cliques in a triangulation of the original graphical model. The title refers to so-called “paranormal” methods which are also used for discrete graphical models.
(really what they want is a triangulation of the graph) and then show that indeed, the inverse covariance matrix does respect the graph structure in a sense. More carefully, they have to augment the variables with the power set of the maximal cliques in a triangulation of the original graphical model. The title refers to so-called “paranormal” methods which are also used for discrete graphical models.
V. Kanade, Z. Liu, B. Radunovic
Distributed Non-Stochastic Experts
This was a star-network with a centralized learner and a bunch of experts, except that the expert advice arrives at arbitrary times — there’s a tradeoff between how often the experts communicate with the learner and the achievable regret, and they try to quantify this tradeoff.
M. Streeter, B. McMahan
No-Regret Algorithms for Unconstrained Online Convex Optimization
There’s a problem with online convex optimization when the feasible set is unbounded. In particular, we would want to know that the optimal  is bounded so that we could calculate the rate of convergence. They look at methods which can get around this by proposing an algorithm called “reward doubling” which tries to maximize reward instead of minimize regret.
is bounded so that we could calculate the rate of convergence. They look at methods which can get around this by proposing an algorithm called “reward doubling” which tries to maximize reward instead of minimize regret.
Y. Chen, S. Sanghavi, H. Xu
Clustering Sparse Graphs
Suppose you have a graph and want to partition it into clusters with high intra-cluster edge density and low inter-cluster density. They come up with nuclear-norm plus 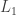 objective function to find the clusters. It seems to work pretty well, and they can analyze it in the planted partition / stochastic blockmodel setting.
objective function to find the clusters. It seems to work pretty well, and they can analyze it in the planted partition / stochastic blockmodel setting.
P. Shenoy, A. Yu
Strategic Impatience in Go/NoGo versus Forced-Choice Decision-Making
This was a talk on cognitive science experimental design. They explain the difference between these two tasks in terms of a cost-asymmetry and use some decision analysis to explain a bias in the Go/NoGo task in terms of Bayes-risk minimization. The upshot is that the different in these two tasks may not represent a difference in cognitive processing, but in the cost structure used by the brain to make decisions. It’s kind of like changing the rules of the game, I suppose.
S. Kpotufe, A. Boularias
Gradient Weights help Nonparametric Regressors
This was a super-cute paper, which basically says that if the regressor is very sensitive in some coordinates and not so much in others, you can use information about the gradient/derivative of the regressor to rebalance things and come up with a much better estimator.
K. Jamieson, R. Nowak, B. Recht
Query Complexity of Derivative-Free Optimization
Sometimes taking derivatives is expensive or hard, but you can approximate them by taking two close points and computing an approximation. This requires the function evaluations to be good. Here they look at how to handle approximate gradients computed with noisy function evaluations and find the convergence rate for those procedures.
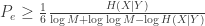
 binary string, and connect two vertices if the two strings have a longest common subsequence of length at least
binary string, and connect two vertices if the two strings have a longest common subsequence of length at least 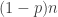 . If two strings are connected then they can’t be in the same code since an adversary could delete
. If two strings are connected then they can’t be in the same code since an adversary could delete 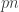 bits and create the common subsequence (note : not substring). So you can get a bound on the capacity by getting a bound on the largest independent set in this graph. So then you can use…
bits and create the common subsequence (note : not substring). So you can get a bound on the capacity by getting a bound on the largest independent set in this graph. So then you can use… 