Proof by figure.

Proof by figure.
I am a big supporter of robust peer review. However, I feel very strongly that issuing short review deadlines weakens the review process and has a negative impact on the quality of research. I had a previous experience with a machine learning conference that assigned 9 papers requiring an in-depth review and was given less than 3 weeks to complete these reviews. I immediately wrote back saying that this was infeasible and the deadline was extended by more than a week, as I recall. It was still hard to get the reviews done on time, but I managed it.
People may think I am being petty here, but I think it is important to not get caught in the dilemma of “phone it in and get it done by the deadline” and “pull some all-nighters to get it done right.”
I regret to inform you that I must resign from the Technical Program Committee for GlobalSIP because I will be unable to complete reviews required of me in the time required by the conference.
On July 12 at around 11:45 EST I was assigned 12 papers to review for the conference, for a total of around 60 pages of material (including references). The deadline given was “before July 22, 2015 (AoE)” which I take to mean approximately 8 AM EST July 22 given the location international date line. This is around 9 days to review 12 papers.
At that time I responded indicating that given my other responsibilities, I would be unable to review such a large volume of material at such short notice in the given time frame. I received no response.
On July 15 at 12:33 AM I received a second request to review the same papers with a revised deadline of “before July 25, 2015 (AoE)”. That is, 2 days after the initial assignment, the deadline was extended by 3 days.
Given my other professional and personal commitments, I will not be able to provide the level of scrutiny required to review the papers in under two weeks. As it stands, the modest extension covering 3 additional business days is not enough, especially given the delay in issuing the extension. I realize that conference submissions do not entail the same depth of review as a journal paper, but they still take time, and the review requests came quite unexpectedly.
Finally, I recognize that the delay in assignment was caused by “system glitches” (as stated in your email) and is not the fault of the PC chairs. However, the brunt of the effect is faced by the reviewers. Without any prior communication or information regarding the delay in review assignments, I am not able to juggle/move/delay other obligations at such short notice.
Anand D. Sarwate
Assistant Professor
Department of Electrical and Computer Engineering
Rutgers, The State University of New Jersey
asarwate@ece.rutgers.edu
http://www.ece.rutgers.edu/~asarwate/
Chicago performance group Manual Cinema has a performance running for another week down in the Financial District at 3LD Arts and Technology Center. It’s a co-production with The Tank, a great nonprofit that supports the development of new works. The show uses 4 overhead projectors, a live band, and actors to make a dialogue-free live-created shadow-play animation, complete with sound effects. The overall aesthetics reminded me of Limbo, an independent game, although less zombie-filled. The story is about two sisters, Ada, and Ava. Ava passes away and Ada has to cope with the grief of losing someone so close to her. We go through her memories of their time together and her fantasies light and dark as she mourns and perhaps begins to heal.
I don’t have too much to say except to recommend it highly. If I had one critique it would be that I wanted the story to be more surprising, or revelatory. The medium is at the same time familiar (animation) and new (live performance). They can show so many things and use metaphor (sometimes a bit heavy-handed in a 1940s way) in ways that a conventional play with dialogue would be hard-pressed to do. I wanted to learn something new about grieving, and afterwards I felt like I hadn’t. But then again, I’m still thinking about it, so perhaps I cannot yet put what I have learned into words.
The advantage of flying to Hong Kong from the US is that the jet lag was such that I was actually more or less awake in the mornings. I didn’t take such great notes during the plenaries, but they were rather enjoyable, and I hope that the video will be uploaded to the ITSOC website soon.
There were several talks on entropy estimation in various settings that I did not take great notes on, to wit:
I would highly recommend taking a look for those who are interested in this problem. In particular, it looks like we’re getting towards more efficient entropy estimators in difficult settings (online, large alphabet), which is pretty exciting.
QUICKEST LINEAR SEARCH OVER CORRELATED SEQUENCES
Javad Heydari, Ali Tajer, Rensselaer Polytechnic Institute, United States
This talk was about hypothesis testing where the observer can control the samples being taken by traversing a graph. We have an 

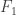
MISMATCHED ESTIMATION IN LARGE LINEAR SYSTEMS
Yanting Ma, Dror Baron, North Carolina State University, United States; Ahmad Beirami, Duke University, United States
The mismatch studied in this paper is a mismatch in the prior distribution for a sparse observation problem 


SEARCHING FOR MULTIPLE TARGETS WITH MEASUREMENT DEPENDENT NOISE
Yonatan Kaspi, University of California, San Diego, United States; Ofer Shayevitz, Tel-Aviv University, Israel; Tara Javidi, University of California, San Diego, United States
This was another search paper, but this time we have, say, 

![S_n \subseteq [0,1]](https://s0.wp.com/latex.php?latex=S_n+%5Csubseteq+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)








![\log(1/\delta) / \mathbb{E}[\tau]](https://s0.wp.com/latex.php?latex=%5Clog%281%2F%5Cdelta%29+%2F+%5Cmathbb%7BE%7D%5B%5Ctau%5D&bg=ffffff&fg=333333&s=0&c=20201002)

ON MODEL MISSPECIFICATION AND KL SEPARATION FOR GAUSSIAN GRAPHICAL MODELS
Varun Jog, University of California, Berkeley, United States; Po-Ling Loh, University of Pennsylvania, United States
The graphical model for jointly Gaussian variables has no edge between nodes 

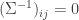
CONVERSES FOR DISTRIBUTED ESTIMATION VIA STRONG DATA PROCESSING INEQUALITIES
Aolin Xu, Maxim Raginsky, University of Illinois at Urbana–Champaign, United States
Max gave a nice talk on the problem of minimizing an expected loss ![\mathbb{E}[ \ell(W, \hat{W}) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Cell%28W%2C+%5Chat%7BW%7D%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)






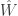
More on Shannon theory etc. later!
