I’ve been derelict since starting my new job in writing in the blog. However, a goal for the summer is to do things worth talking about. More soon, but it might be some throat clearing with links, CFPs, and whatnot. Plus a bugfix pointed out by Yihong.
Tag Archives: self-indulgence
Linkage
This NSF report from the Office of the Inspector General has some really horrendous examples of data fabrication, plagiarism, and other misconduct by PIs and graduate fellowship (GRFP) recipients. It’s true that bad behavior taints the whole program: how good is the GRFP selection process if students like this get awards?
This article on Bhagat Singh Thind is fascinating. We need a modern Ghadar Party here. But this is so bizarre: “[o]ut of necessity and ingenuity, Thind, along with several dozen South Asians during the interwar decades reinvented themselves as itinerant spiritual teachers and metaphysical lecturers who would travel from city to city, giving lectures and holding private classes.”
A photo gallery by Lotfi Zadeh: some of these are really beautiful portraits. Also the variety! I remember not really understanding portraiture when I was younger but I think I “get it” a bit more now. Or at least why it’s interesting. There’s even a photo of Claude Shannon… from the email:
Prof. Lotfi Zadeh, who passed away in 2017, was an avid photographer who grew up in a multicultural environment, surrounded himself with a cosmopolitan crowd, and always kept his mind open to new ideas. In the 1960s and 70s, he enjoyed capturing the people around him in a series of black and white portraits. His burgeoning career gave him access to a number of artists, academics, and dignitaries who, along with his colleagues, friends, and family, proved a great source of inspiration for him.
THE SQUIRCLE IS SO FASCINATING!
I helped organize a workshop at IPAM on privacy and genomics. Videos (raw) are up now.
NIPS 2017 Tutorial on Differential Privacy and Machine Learning
Kamalika and I gave a tutorial at NIPS last week on differential privacy and machine learning. We’ve posted the slides and references (updates still being made). It was a bit stressful to get everything put together in time, especially given how this semester went, but it was a good experience and now we have something to build on. It’s amazing how much research activity there has been in the last few years.
One thing that I struggled with a bit was the difference between a class lecture, a tutorial, and a survey. Tutorials sit between lectures and surveys: the goal is to be clear and cover the basics with simple examples, but also lay out something about what is going on in the field and where important future directions lie. It’s impossible to be comprehensive; we had to pick and choose different topics and papers to cover, and ended up barely mentioning large bodies of work. At the same time, it didn’t really make sense to put up a slide saying “here are references for all the things we’re not going to talk about.” If the intended audience is a person who has heard of differential privacy but hasn’t really studied it, or someone who has read this recent series of articles, then a list without much context is not much help. It seems impossible to even make a real survey now, unless you make the scope more narrow.
As for NIPS itself… I have to say that the rapid increase in size (8000 participants this year) made the conference feel a lot different. I had a hard time hearing/understanding for the short time I was there. Thankfully the talks were streamed/recorded so I can go back to catch what I missed.
Postdoctoral Position at Rutgers with… me!
I keep posting ads for postdocs with other people but this is actually to work with little old me!
Postdoctoral Position
Department of Electrical and Computer Engineering
Rutgers, The State University of New Jersey
The Department of Electrical and Computer Engineering (ECE) at Rutgers University is seeking a dynamic and motivated Postdoctoral Fellow to work on developing distributed machine learning algorithms that work on complex neuroimaging data. This work is in collaboration with the Mind Research Network in Albuquerque, New Mexico under NIH Grant 1R01DA040487-01A1.
Candidates with a Ph.D. in Electrical Engineering, Computer Science, Statistics or related areas with experience in one of
- distributed signal processing or optimization
- image processing with applications in biomedical imaging
- machine learning theory (but with a desire to interface with practice)
- privacy-preserving algorithms (preferably differential privacy)
are welcome to apply. Strong and self-motivated candidates should also have
- a strong mathematical background: this project is about translating theory to practice, so a solid understanding of mathematical formalizations is crucial;
- good communication skills: this is an interdisciplinary project with many collaborators
The Fellow will receive valuable experience in translational research as well as career mentoring, opportunities to collaborate with others outside the project within the ECE Department, DIMACS, and other institutions.
The initial appointment is for 1 year but can be renewed subject to approval. Salary and compensation is at the standard NIH scale for postdocs.
To apply, please email the following to Prof. Anand D. Sarwate (anand.sarwate@rutgers.edu):
- Curriculum Vitae
- Contact information for 3 references
- A brief statement (less than a page!) addressing the qualifications above and why the position is appealing.
- Standard forms: Equal Employment Opportunity Data Form [PDF] Voluntary Self-Identification of Disability Form [PDF] Invitation to Covered Veterans to Self-Identify [PDF].
Applications are open until the position is filled. Start date is flexible but sometime in Fall 2016 is preferable.
Rutgers, The State University of New Jersey, is an Equal Opportunity / Affirmative Action Employer. Qualified applicants will be considered for employment without regard to race, creed, color, religion, sex, sexual orientation, gender identity or expression, national origin, disability status, genetic information, protected veteran status, military service or any other category protected by law. As an institution, we value diversity of background and opinion, and prohibit discrimination or harassment on the basis of any legally protected class in the areas of hiring, recruitment, promotion, transfer, demotion, training, compensation, pay, fringe benefits, layoff, termination or any other terms and conditions of employment.
LabTV Profiles Are Up!
And now, a little pre-ITA self-promotion. As I wrote earlier, LabTV interviewed me and a subset of the students in the lab last semester (it was opt-in). This opportunity came out of my small part in the a large-scale collaboration organized by Mind Research Network (PI: Vince Calhoun) on trying to implement distributed and differentially private algorithms in a system to enable collaborative neuroscience research. Our lab profiles are now up! They interviewed me, graduate students Hafiz Imtiaz, Sijie Xiong, and Liyang Xie, and an undergraduate student, Kevin Sun. In watching I found that I learned a few new things about my students…
Starting up, and some thoughts on admissions
It’s been a busy January — I finished up a family vacation, moved into a new apartment, helped run the MIT Mystery Hunt, started teaching at Rutgers, and had two conference deadlines back to back. One of my goals for the year is to blog a bit more regularly — I owe some follow-up to my discussion of the MAP perturbation work, which I will be talking about at ITA.
In the meantime, however, one of the big tasks in January is graduate admissions. I helped out with admissions at Berkeley for 4 years, so I’m familiar with reviewing the (mostly international) transcripts, but the level of detail in transcript reporting varies widely. The same is true for letters of recommendation. I’m sure this is culturally mediated, but some recommenders write 1-2 sentences, and some write paeans. This makes calibrating across institutions very difficult. While the tails of the distribution are easy to assess, decisions about the middle are a bit tougher.
Rutgers, like many engineering school across the country, has a large Masters program. Such programs serve as a gateway for foreign engineers to enter the US workforce — it’s much easier to get hired if you’re already here. It’s also makes money for the university, since most students pay their own way. In that regards, Rutgers is a pretty good deal, being a state school. However, it also means making admissions decisions about the middle of the distribution. What one wants is to estimate the probability an applicant will succeed in their Masters level classes.
It’s a challenging problem — without being able to get the same level of detail about the candidates, their schools, and how their recommenders feel about their chances, one is left with a kind of robust estimation problem with a woefully underspecified likelihood. I’ve heard some people (at other schools) discuss GPA cutoffs, but those aren’t calibrated either. More detail about a particular individual doesn’t really help. I think it’s a systemic problem with how graduate applications work in larger programs; our model now appears better suited to small departments with moderate cohort sizes.
Linkage
I’m in the process of moving to New Jersey for my new gig at Rutgers. Before I start teaching I have to go help run the the Mystery Hunt, so I am a little frazzled and unable to write “real” blog posts. Maybe later. In the meantime, here are some links.
The folks at Puzzazz have put out a bevy of links for the 200th anniversary of the crossword puzzle.
The UK has issued a pardon to Alan Turing, for, you know, more or less killing him. It’s a pretty weasely piece of writing though.
An important essay on women’s work: “…women are not devalued in the job market because women’s work is seen to have little value. Women’s work is devalued in the job market because women are seen to have little value.”. (h/t AW)
Of late we seem to be learning quite a bit about early hominins and hominids (I had no idea that hominini was a thing, nor that chimps are in the panini tribe, nor that “tribe” is between subfamily and genus). For example,
they have sequenced some old bones in Spain. Extracting sequenceable mitochondrial DNA is pretty tough — I am sure there are some interesting statistical questions in terms of detection and contamination. We’ve also learned that some neanderthals were pretty inbred.
Kenji searches for the perfect chocolate chip cookie recipe.
A new job for me
I’m happy to announce that in January 2014 I will be joining the Electrical and Computer Engineering Department at Rutgers, The State University of New Jersey, as an Assistant Professor.
My current job
I’ve had to do a lot of explaining about my current position and institution since moving here, especially when I go visit ECE departments. So I figured I might use the blog to give a quick rundown of the job. I’m a Research Assistant Professor at the Toyota Technological Institute at Chicago, a philanthropically endowed academic computer science institute located on the University of Chicago campus.
- The Toyota Technological Institute at Chicago is a branch of the Toyota Technological Institute in Nagoya, Japan. Their website is a little slow to load, but the Wikipedia entry has more quick facts. TTI-Japan was founded through an endowment from the Toyota Motor Corporation in 1981 (so it’s younger than me). The Toyota Motor Corporation is not my employer, although some executives are on the board of the school.
- I do not work for Toyota. My research has nothing to do with cars. At least not intentionally.
- TTI-Chicago is basically a stand-alone computer science department and was started in 2003. It only has graduate students and grants its own degrees. It happens to be located on the University of Chicago campus — we rent two floors of a building which also contains the IT services. Classes at TTI are cross-listed with the University of Chicago — students at TTI take classes at UChicago and students at UChicago take classes at TTI.
- I get an “affiliate” card for UChicago which lets me use the library and stuff. It’s great to have a library there, but since UChicago has no engineering, my access to IEEExplore is a bit limited.
- The research at TTI-Chicago is mostly in machine learning, computer vision, speech processing, computational biology, and CS theory. This makes me a bit of an odd-one-out, but I have been doing more machine learning lately. It’s fun learning new perspectives on things and new problems.
- The Research Assistant Professor position at TTI-Chicago is a 3-year position (some people have stayed for 4) which pays a 9 month salary (out of general institute funds) and gives a yearly budget for research expenses like travel/conferences and experimental costs (e.g. for Mechanical Turk or Amazon EC2). It’s not a “soft money” position but people are free to raise their summer salary through grants (like I did) or by taking a visiting position elsewhere for part of the year. I do not have to teach but can offer to teach classes or help teach classes
- There are tenure-track faculty at TTI, and it’s the same tenure deal as elsewhere. Their teaching load is one quarter per year (that should make people jealous).
- There are graduate students here, but not a whole lot of them. I can’t directly supervise graduate students but I can work with them on research projects. I’m starting to work with one student here and I’m pretty excited about our project.
Upper bounds for causal adversaries
Bikash Dey, Mike Langberg, Sid Jaggi, and I submitted an extended version of our (now accepted) ISIT paper on new upper bounds for binary channels with causal adversaries to the IT Transactions. The model is pretty straightforward : Alice (the encoder) transmits a message to Bob (the receiver) encoded over 
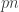

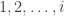
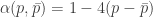
![C \le \min_{\bar{p} \in [0,p]} \left[ \alpha(p,\bar{p})\left(1-H\left(\frac{\bar{p}}{\alpha(p,\bar{p})}\right)\right) \right]](https://s0.wp.com/latex.php?latex=C+%5Cle+%5Cmin_%7B%5Cbar%7Bp%7D+%5Cin+%5B0%2Cp%5D%7D+%5Cleft%5B+%5Calpha%28p%2C%5Cbar%7Bp%7D%29%5Cleft%281-H%5Cleft%28%5Cfrac%7B%5Cbar%7Bp%7D%7D%7B%5Calpha%28p%2C%5Cbar%7Bp%7D%29%7D%5Cright%29%5Cright%29+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
This is what it looks like:

Plot of the new upper bound
So clearly causal adversaries are worse than i.i.d. noise (the
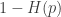 bound).
bound).
To show such a bound we have to propose a new attack for the adversary. We call our attack “babble and push.” It operates in two phases. The first phase is of length 

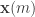

- (Babble) Calvin chooses a random subset
indices uniformly from all
-subsets of
and flips bit
.
- (Push) Calvin finds all possible codewords which are consistent with what Bob has received in the first phase:
,
and selects an element
uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards
— if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability
.
Analyzing this scheme amounts to showing that Calvin can render the channel “symmetric.” This is a common condition in arbitrarily varying channels (AVCs), a topic near and dear to my heart. Basically Bob can’t tell the difference between the real codeword and the transmitted codeword, because under Calvin’s attack, the chance that Alice chose 


It’s relatively clear that this approach would extend to more general AVCs, which we could work on for the future. What is neat to me is that this shows how much value Calvin can derive by knowing the current input bit — by forcing additional uncertainty to Bob during the babble phase, Calvin can buy some time to more efficiently use his bit flipping budget in the second phase.
